Hi,
I was inspired by the Magus code to predict movements on Coders Strike back.
It works well except when I increase or decrease the angles by exactly 18°.
In this case I get (very small) prediction errors probably due to rounding errors on the starting angle.
Please, do you have any ideas on how to fix this problem ?
Hey,
Been playing this one for fun. Looking at games, I’ve seen something strange. Here’s the replay : https://www.codingame.com/replay/448051259
Red is my bot. The first one is asked to boost on the first turn; the second one starts normally.
But look at the Yellow team. Both bots are accelerating very fast, both of them are under boost.
BEFORE EDIT
Tried to reproduce that with my bots but as expected (by the rules), I can’t.
Question : how did the yellow team managed that ?I’m really intersted for input on the underlying bug, if any (probably even more than by the fix itself :p).
EDIT
Nevermind, I reproducted that. Re-read the rules. It appears that the number of boosts being common to the group doesn’t mean that there’s only a single boost by team; there’s one boost, by pod. Up to two boosts, so

Best regards
K.
1 Like
I am # 1 in my league and beat the boss but I’m not advancing to the next league. Can anyone tell me why that might be? (Wood 1 league)
You have been promoted. You need to wait for all your battles to be completed before getting promoted.
1 Like
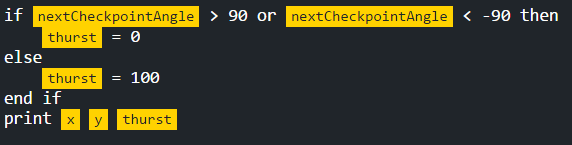
How do you change the thrust in console.log(nextcheckpointX +nextCheckpointY + ' 50'); ?
Change the 50 to something higher
Also, i kept getting “ValueError: too many values to unpack (expected 4)
at Answer.py. in on line 15” Does anybody know how to fix this? I’m terrible at coding and I only just finished the tutorial, and I haven’t tampered with any of the code except for the last line. I am using python 3
1 Like
Had the same problem, changed the language to JavaScript and it worked normally
Okay when I changed back to Python 3 I noticed there was an extra line added after line 15:
“opponent_x, opponent_y = [int(i) for i in input().split()]”
I hit play my code and it is working!
Yeah, I copied the meat of my code and hit the “reset to default” button, and pasted the code into where it was supposed to go and it worked normally. I think there’s something about the transition between leagues and the addition of new functions that messes with the code a little bit, but a reset to your code seems to do the trick.
Finally reached Legend! It was quite a journey. I’m satisfied with my result, top 200.
But I have several things to clear in my mind.
I gathered a lot of information from the blog posts. At the end I’m using GA. I’m simulating 8 turns ahead. And I use single chromosome per team.
Each turn I first simulate the enemy pods for about 60 populations, considering my pods are still, maximizing the enemy checkpoints count and minimizing the distance for each enemy to its next checkpoint. Kind of like racing for time.
After the enemy GA is complete I store the best enemy chromosome from the last population and start simulating my pods. I simulate them for about 100 populations. Each time I move my pods I also move the enemies, getting the enemy action from its best chromosome. Now the evaluation considers runner and hunter pods for each team, maximizing the score for my runner and minimizing the score for the enemy runner. The simulation looks like this(blue lines are the enemy paths, green ones are mine):

Тhis raises many questions:
First of all, I’m considering the enemy races for time, but what about if the enemy uses completely different strategy, if so would my simulations still hold some correct information. I image the best solution would be to somehow analyze the previous turns for the enemy and determine his strategy!?
Second I’m wondering if simulations for my pods are correct, when collisions with the enemy accrues, since I’ve simulated the enemy alone. After a collision the whole path for the enemy may change and the next action for the enemy may mean complete gibberish.
Also I’m wondering if the simulations hold meaningful information when the enemy pods are too far from mine, which happens very very often. Simulating several turns ahead will require very strong evaluations function to compensate the big distance between pods, right?
The biggest problem I have is to use the allowed turn time well. My algorithm now takes around 50ms per turn. If I increase the populations sizes, after certain amount of populations, all chromosomes are converging to the optimal solution based, on my evaluation function, which most often is not very good. If I lower the populations sizes for enemy and my simulation I could simulate many more turns ahead, sometimes I’ve reached simulations above whole lap. But strangely as I increase the simulated turns my pods are playing more and more carefully, the runner is slow the hunter is not aggressive… Has this ever happened to anyone!? Maybe it’s a bug in my evaluation function, which I cannot see.
I think my current algorithm has a lot of potential, but requires a lot of fine tuning, which I suppose will come with experience in multiplayer games.
I know that the top players use DFMonteMax tree search algorithms variations. And I gave it a try. At each depth trying 6-9 actions per pod then at depth % 4 == 0 simulating all pods and evaluating the game state:
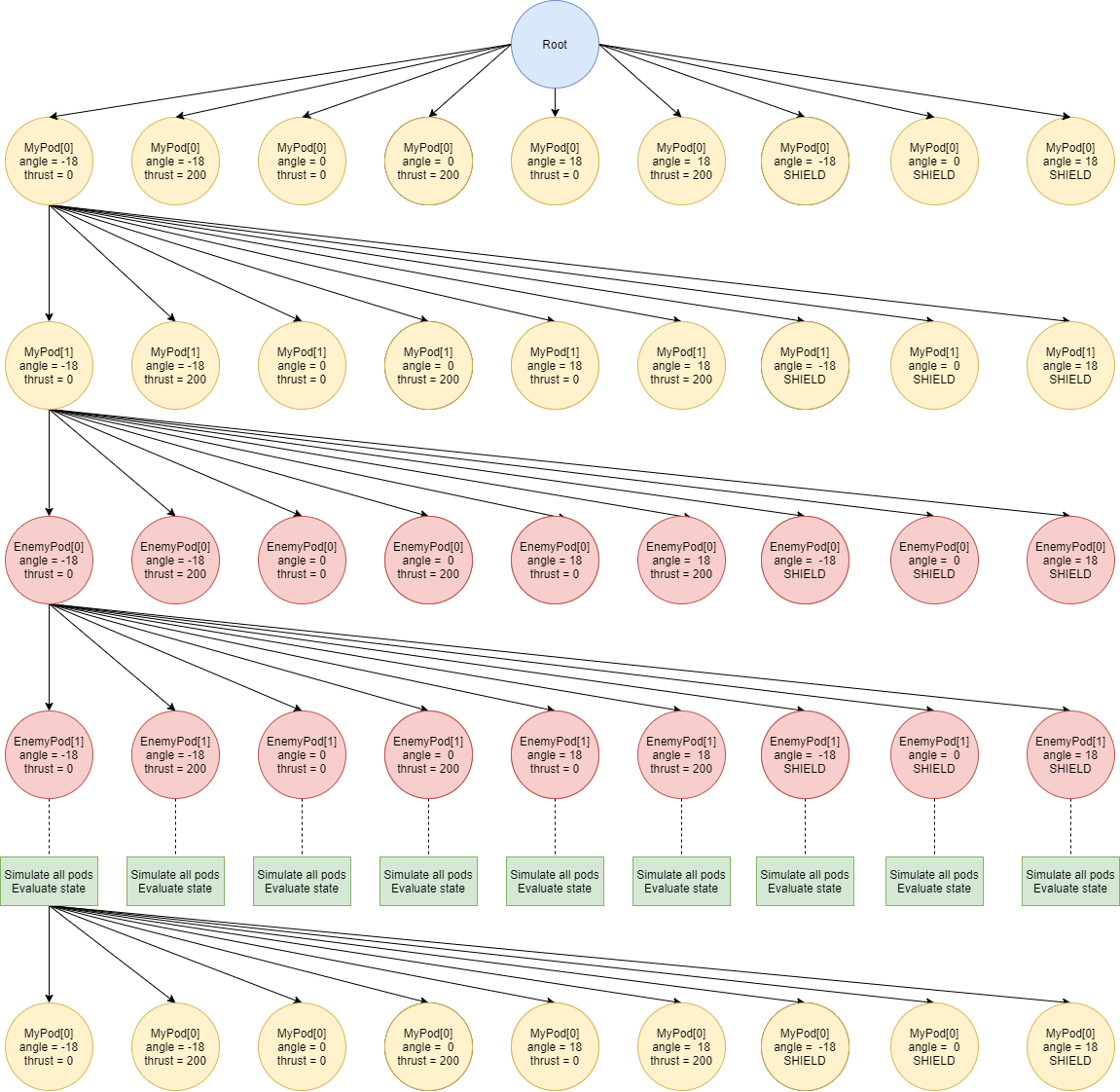
{kind=link}
No matter how much I prune the tree or actions I couldn’t get more than one turn depth search or I did but the pods were very clumsy. I thought of using different search trees for each pod, but I just cannot imagine how these trees would work simultaneously. How would my pods consider enemy actions if they are in another tree!? And many other questions. Now I’m reading about MonteCarlo tree search and after that I may revisit my tree search for this game.
In both strategies I realized that I need very good evaluation function. It seems to me that finding one is as much effort as implementing everything else. How do you tune your evaluation functions? Often when I try to modify mine a little bit, the behavior of the whole algorithm changes in bad direction, pods go out of the map, wondering around like hungry birds, one time my own pods start to fight each other.
The most interesting moment in my implementation was the searching for a bug almost 3 days and at the end it appeared to be uninitialized float. On my local machine it was always 0.f but in CodinGame sometimes it wasn’t 
The game is really good, but indeed is very hard to master.
6 Likes
what to do in coders strike fight with boss 2 ?
Can we now the radius of the checkpoint?
Its 3 lap round sir !
For boss 2 it says the angle is between -180 and 180, but when I log it with cerr it has values up to 7500. What’s up with that?
I see a lot of talk on this forum that you need to use some fancy genetic algorithm, neural network, or similar method to reach the the top position. That might be so, but you can get very far without it. I am now at rank 380 in the Legends League and I have only being doing heuristic code (=basic scripting) based on ideas on what might work and observing bouts and thinking about how my pods should behave differently. I didn’t read any blog posts or get tips on the net. I think I can get even higher in ranking this way, but enough is enough and now I am moving to a new challenge. It was fun for a few weeks, but now it is time for me to move on. The spring challenge 2020 maybe?
2 Likes
It says in the rules (maybe only at higher leagues). It says: “The checkpoints are circular, with a radius of 600 units.”
1 Like
Hi!
I don’t know if it’s only a problem for Coders Strike Back, but when I use the error_log() function, it displays two times the message, which leads to a difference of turn between what’s diplayed using error_log() and echo.
I’m using PHP as language.
But why they told that thrust = BOOST? What does it.mean?
And then the opponent had the boost. How can i use BOOST?