Hello,
when I began this puzzle, I could not imagine how much time I will dig into it and how much I will learn from it
Now, I spent some hours to understand your function and I think I managed to delivered one “compress” string encoded in UTF-8
Nevertheless, before I try to code the “decode function”, I have some questions please (forgive my poor english level I’m an “almost old” frenchman ) :
→ Please confirme What is the outputIndex => the “to encode string” length * 4 ?
→ to initialize the outputCompact array I put the string like this uint8_t outputCompact[22000] = { “stringacompresser” }; but I don’t know how to do when the value is too big for the initializer (of course I tried to use a variable but it seems not to compile and I’m autodidact in C++ so I think it lacks me a bit of theory )
→ the most important question : probably i’ve missed something but when I put a 10 k string to test, the result is a 5 K string => I need to reduced my hardcoded string to 3K max so I believed I made a mistake somewhere
In parallel, I developed my own ‘naive’ function to encode/decode which is based on the idea to encode all the 3 char combinaisons of U/D/R/L (4^3 = 64) so I can “merely” divide my string by 3 but it’s not sufficient for the moment.
I will explore your idea to use all the utf-8 scope to divide at least by 5 (4^5 = 1024) even by 6 (4^6 = 4096) but for the moment I don’t know how to do that and it’s the next step with the help of your example.
At Last, my macbook pro is under pressure, because i’m trying to find the biggest score using your calculation array above to know how much is the maximum (and it seems that my simulation is about to find almost the biggest score). I gave him for one turn, 300 sec to explore 65536 simulated branches and now it has calculated 82 turns, it obtains a score of 1 280 020 / 1 747 288 and the calculation is not achieved …
Infortunately, as you see with these informations, it has very very very bad performance and i need to improve my code but I’m very happy to begin approaching your scores with my own simulator and fitness function
For my curiosity, how much time do you need to calculate the whole string for the max score on the 290797 seed please ?
to illustrate a capture of my simulation running and generating string for each turn and the score at the end of the 300 sec, at the end I have one big string that I need to compress to 3K max
The outputindex is the index of the move. So if it’s the 10th move, that’ll be 9. You divide by 4 because there’s 4 moves in a byte.
Dont really understand what happened with your string size, but I’ll share a full program for encoding and decoding when I have a bit more time. Currently spending my days trying to win at a contest. I’ll have more time after thursday. I’ll reply here when I have it.
The 290797 seed I do online, so it’s less than 30 seconds. Maybe less than 20. I don’t actually calculate a string either, because it’s not hardcoded. I just fill an array with moves for that one.
I think you’d be better served by focusing on a better online solver. It really should be able to get the maximum online for half the cases. Did you learn about the snake evaluation?
Thank you for taking time to answer my questions !
I did my own “naive” fitness function so i didn’t know “snake evaluation”, for the moment I obtained a score of 1 650 892 on the seed 290797 and gain some places but my priority was to understand how compressing all this moves (40 736 moves for 1 650 892 pts)
I will continue to dig into it and trying to improve it
Hello,
thanks to you, I studied snake evaluation and I mixed it with my own one (which was essentially a “merge + empty + sum”) and I added a bit of random to diversify the search + a little optimisation + good compilation options ( ) and now I almost found the best solution (on my Mac for the moment) in few seconds (same time_limit than CG in my simulator) !
Now, I need to understand how to improve it because the results are too random (my search pruning method is not precise)
From what I remember, the snake is all that matters. Those other features that are mentioned in papers and such don’t help. Be sure to rotate and mirror your snake. Try a solution with all 8 possible evals and see which gives the highest score. You can do this locally and then online, all you have to do is select the best one.
Hi,
I implement the 8 snakes matrix, it’s was funny …
Nevertherless, I always need to “inject” my own evaluation (in particularly the merge evaluation is very important) and a big random number which is very very efficient to converge quickly (I’m not sure but I suppose it permit to find solutions which were rejected otherwise)
If I don’t do these two additions then my scores with only 8’s snakes are weak
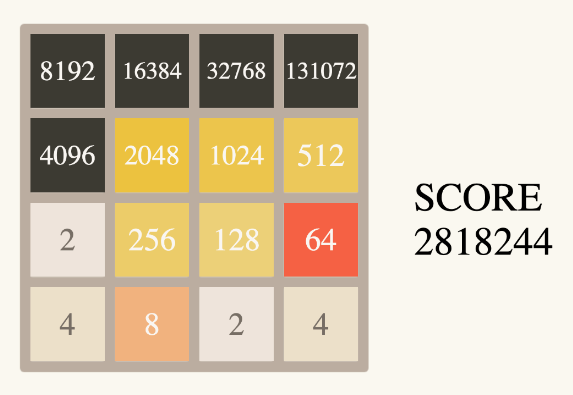
the biggest seed (41359522) calculated offline on my Mac, 3 x compress and push on CG give that screen, it’s the best score I’ve ever obtained
Good job. Here’s my unicode-compression code. This is a full working program. It’s just compressing bytes into unicode characters as compactly as I can imagine and then back to a normal array again. It is up to you how you want to pack the information into the bytes.
Nevertheless, it illustrates what I was saying the other day : you converted 256 bytes in 138 char it’s a 50 % ratio isn’t it ? And it’s the ratio I found when I tried to use your code
How do you do to hardcoded 60k moves in CG with a 50 % ratio ? it means that you could only push three hardcoded string (30 k * 3 => 100 k limit)
My own compression method divide by 3 (I’ve a dictionary with all 3 char combinaisons from U/D/L/R encoded in 64 (4^3) differents chars (from char(33) to char(99) minus “” and ') so for a 60 k moves I can push only 20 K but my goal is to obtain 3 Ko (100 k / 29 cases) )
I made a pause but I will continue to try to find the best compress algorithm (I’m exploring “bits-field” repetition U = 0 (b00), D = 1 (b01), L = 2 (b10), R = 3 (b11) but I don’t know how to do that for the moment)
Have a good day !
PS : I’m looking for a best compression algo because now I don’t know how to improve my online score without that. I’ve tried so many ideas
PS 2 : my own naive compression code (x3) (in CG I just use the DictionnaireDecode function.)
by example with “RRUUULLDDDDDURDLDUDDR”, I obtain “J%W7+V8”
#pragma GCC optimize "O3,omit-frame-pointer,inline"
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <chrono>
#include <map>
#include <codecvt>
#include <fstream>
using namespace std;
string aCompresser="RRUUULLDDDDDURDLDUDDR"; // exemple => J%W7+V8
inline string afficherCoup(const int &coup) {
switch (coup) {
case 0:
return "U";
case 1:
return "D";
case 2:
return "R";
case 3:
return "L";
}
return "U";
}
map <string,int> DictionnaireEncode;
map <int,string> DictionnaireDecode;
int main(int argc, const char * argv[]) {
int dico = 33;
//initialisation du dico avec les cas "de base"
string coup="";
for (int i = 0; i < 4; i++) {
for (int j = 0; j < 4; j++) {
for (int k = 0; k < 4; k++) {
if (dico == 34 || dico == 92) {
dico++;
}
coup = afficherCoup(i)+afficherCoup(j)+afficherCoup(k);
DictionnaireEncode[coup] = dico;
DictionnaireDecode[dico] = coup;
dico++;
}
}
}
cerr <<"Taille originale : "<<aCompresser.length()<<endl;
//compresser ici
wstring chaineCompressee = L"";
for (int i = 0; i < aCompresser.length(); i += 3) {
string coupMulti = aCompresser.substr(i,3);
if (auto search = DictionnaireEncode.find(coupMulti); search != DictionnaireEncode.end()) {
cerr << "conversion trouvée : "<<search->first<<" -> "<<char(search->second)<<endl;
chaineCompressee += char(search->second);
}
}
//afficher ici la chaine compressée et sa taille
//cerr <<chaineCompressee<<endl;
cerr <<"Taille nouvelle : "<<chaineCompressee.length()<<endl;
const std::locale utf8_locale = std::locale(std::locale(), new std::codecvt_utf8<wchar_t>());
wofstream fC(L"C_Seed_xxxxx.txt");
fC.imbue(utf8_locale);
fC << chaineCompressee << endl;
fC.close();
//decompresser ici
wstring chaineDeCompressee = L"";
for (int i = 0; i < chaineCompressee.length(); i++) {
int coupMulti = chaineCompressee[i];
if (auto search = DictionnaireDecode.find(coupMulti); search != DictionnaireDecode.end()) {
cerr << "conversion trouvée : "<<char(search->first)<<" -> "<<search->second<<endl;
chaineDeCompressee += search->second[0];
chaineDeCompressee += search->second[1];
chaineDeCompressee += search->second[2];
}
}
//vérifier que la chaine décompressée = chaine compressée
cerr <<"Taille chaine reconstruite : "<<chaineDeCompressee.length()<<endl;
wofstream fD(L"D_Seed_xxxxx.txt");
fD.imbue(utf8_locale);
fD << chaineDeCompressee << endl;
fD.close();
}
That depends on how you define your ratio. In my method 1 byte holds 4 moves. For example: “UDRL” can be 1 byte (2 bits each move). So that sense it is a 13.5% ratio. You can fit 7,4 moves in 1 character.
In case you’re not used to bitboards:
00 = U
01 = D
10 = R
11 = L
UDRL → 00011011 (1 byte)
That would mean I can do a total of around 600-700k moves in close to 100k characters. That’s not enough to hardcode everything, but I don’t need to. Half my testcases are done online. The other half are done partially online. In fact, my submission only uses around 50k characters, well below the limit.
Hello, I get an error that I don’t understand: in test 209797, I try the string “UDRULURURURULULULURULD” and I get the following error at the 17th character:
I can’t say anything more that exactly what the message says : this action is invalid. Check if you can move anything left in this case, if not, then you will get this message.
How did you do a score over 2000000? What is the technique? PLS.
How to find the new move if it is the end too soon ? I made 100 move each turn
I did 1000000 for all not for one.
I ve a problem on this Puzzle.
Say i’m hardcoding, when i’m not. I’m currently stuck at 15M points with snake evaluation, and i would try to at least push the score before touching my algo.
While i’m in fact scoring 24M and should be ranked 48~. But i can’t because they say i’m hardcoding while i’m not. When aml the top score used hardcoding.
How do you know you score 24M? There’s a random seed validator, which I assume changes every time you submit your code.
Also, “hardcoding” is just a general reminder that you may not be able to pass all validators if you hardcode in some ways. There isn’t any actual hardcoding check.
Then, if i post here because i can’t actualise my score, while they say that i’m hardcoding while i’m not… it’s because i need help. How does your responses help me in any way?
How do you know what the random seed validator is?
And if you think me explaining the hardcoding message or asking you for more information isn’t part of helping you, then fine Can’t help you without more information, really.