Congratulations for all the participants. This game was pretty neat and too difficult to understand at the beginning. I did not get a high rank (336 global), but even though I had a lot of fun codding. Thanks to all the people involved to bring this contest to us.
10 Likes
Language : Java
League : Legend
Rank : 23 top3 language
Its my first PM. 
Thank you CG for providing to us this completely unexpected contest. It was funny. Thanks especially to [@_SG_Sebastien].
Thanks to my work that left me a little strength for this contest. This doesn’t happen often.
Thanks to my simulation engine that it didn’t give me a lot of timeouts, as it used to be usually. Thanks [@Wala] and [@Neumann] for tips in [Fall Challenge 2020 - Feedbacks & Strategies - #57 by wala] and [[JAVA] JVM memory issues - #4 by Neumann]. Im not sure that it works, but I used similar code.
The rules are very confusing to understand.  Without Referee, it was very difficult to develop a correct simulation. I passed through a few dead ends, before i wrote, what need to me.
Without Referee, it was very difficult to develop a correct simulation. I passed through a few dead ends, before i wrote, what need to me.
Initial bot
First version of my bot for full rules was heuristic and very simple:
- Make an app release if you don’t have bugs (Technical Debt);
- Do automated bonuses (8), if possible;
- Take bonuses to me at 6;
- Throw out the technical debt at 7;
- Go to nearest available zone.
I was very surprised that he got to the golden league without changes.
Final bot
My bot is BFS “one turn” simulation algorithm and some heuristic improvements.
I developed “lean” version in the beginning (min debts). And it couldn’t get past the golden league boss. Something went wrong and I realized that during the current vision I will never be able to pass it.
Sunday I spent on a new concept. It sounds “huak huak release new issue in production” in Russian.
Main idea: Technical debt doesn’t matter. Deadline comes in 8 months  (moves).
(moves).
How will we release the fifth application? 2 automated skills + 2 automated bonuses and we haven’t problem.
Evaluation function looks like a first bot algorithm (in descending order of value):
- Make an app release + save better apps for fifth release + release applications that are convenient for my competitor (with skills which he automated);
- Take card 2 and play DR, if possible and score = 0;
- Do automated bonuses (need 2 only);
- Do most useful automated skills (if we have 2 automated bonuses);
- Take CI cards if possible;
- Go to nearest available zone.
I added some heuristic tweaks for release 3, 4 and 5 application. If score > 2, bot start to consider moves GIVE. Bot built release pipeline also.
13 Likes
Great contest, some bugs early on, but fast fixes  Solid gameplay and complex rules, just as I like it
Solid gameplay and complex rules, just as I like it 
C#, 31st (just behind a sneaky cat  )
)
My search is a random action as the first action (move/give/throw/play_card/release)
Then 8 full rounds (move->…->Release):
- ~50 % chance of a decent policy (top gold mid week)
- else random action
Then enemy is using the policy for his first 3 moves, then he is moved far away and never to be seen again. Enemy also has no cards to begin with, he was supposed to have, but the state was saved before init -.- And I didn’t have time to fit params on Sunday to allow him to have cards.
Wasted 2 days on local training as the training wasn’t valid (some thread issues with brutal-tester and the referee). Shame on me for not validating that setup with dumb vs smart code initially…
Thx for CG for hosting a free multiplayer game, I had a great time as usual!
15 Likes
#37 legend
I was too lazy to implement something smart like MCTS, Beam search, NN, etc. so I implemented brute force DFS of my turn until I discard cards.
I couldn’t search into all probable states after playing TRAINING or CODING, because I used Kotlin and really didn’t want to optimize anything except hashing states. Instead I added a special parameter equal to usefulCardsICanDraw / allCardsInDrawPile. It brought chaos, but it worked somehow.
I think the most meaningful parameter of evaluation was the “automationScore” equal to the number of unique automated skills multiplied by the number of apps that require that skill.
And the same parameter for the opponent. So I wanted my bot to automate the most potentially useful skills and steal easy apps from the opponent
Funny that it’s my second legend in contests and last time it was also a deck-building game Legends of Code and Magic
10 Likes
That was really unexpected. Thanks Codingame and Société Générale for this fun contest.
A lot of people in the chat were asking themselves if they should bother writing a simulation. For me it was a no brainer. Sure for 2 days (one writing the simulation and one debugging it) you won’t submit any code but it will make your life so much easier. Even for heuristic bots.
The rules were a bit complicated and boring but writing the simulation was not that hard and a nice way to get familiarized with them.
When i code a simulation i put a lot of assertions with the game inputs : Is my simulated state identical with the game one? Do i calculate the same possible moves? …
They show me what i misunderstood. I didn’t even have to look at the referee.
Then i did a beam search.
My game states were byte arrays, with :
- teams values
- card locations
- undone application ids
- simulated actions
- score…
Some values were double or int converted to bytes. Besides being faster than classic objects they’re easy to print and reuse offline.
The opponent was simulated by a dummy :
- It avoided giving cards to the other team
- It made a “short” move to take a “good” card (each zone had a value CI > CODE_REVIEW > REFACTORING > DAILY_ROUTINE…).
I tried to simulate it with the beam search but it was worse.
The main problem with beam search is that you usually end up tweaking evaluation parameters almost without thinking nor results. I couldn’t improve my bot after legend opening.
The other problem was the randomness of the draws. I controlled it a bit by picking my random numbers from a precalculated array and storing an index in my states, so the random numbers would be the same for all the states.But as soon as the number of draws wasn’t the same (due to TRAINING, ARCHITECTURE_STUDY or CODING) the best action could be wrong (don’t do this, because then in 2 moves the draw will be really good…)
I tried to compensate it with some heuristics but without success.
My proudest moment was, of course, when my bot was chosen as gold boss even if it was only for one hour and due to a bug. 
See you all soon.
18 Likes
#33 Legend
My search is MCTS for my first chain of moves and random rollout for both players:
-
MCTS tree contains only my first chain of moves and not expand after release, training, coding action.
-
In random rollouts available moves is pruned and sorter by heuristic: this is the most significant part. In fact, this is copy from my previous bot.
For move phase: distance to zone, penalty for administration, ignore opponent zone, possible release with tech debt <= 2.
For release phase: tech debt <= 2. -
In the end of random rollout i use evaluation function with normalization to 0-1 score and multiply to small discount by depth.
-
Opponent cards is filled randomly each time in rollout part.
-
Max depth is 10x2 chain of moves for both players.
-
I have 1k rollouts and 50k sims.
Thanks to CG for the contest!
15 Likes
95 Gold ~ 20 Gold at one point but last minute submit was a Fail 
First I want to thank CG and SG for this contest, it was my second contest and it proved to be way harder than I expected.
As I’m just beginning in the field of Competitive Programming, this contest made me realize I have a lot of things to learn. Search algorithms, NN, Sims… I have so much to learn.
Wood2 to Bronze
Move phase: Move to next possible desk if the opponent desk not on it, else move to the next one.
Everything else was Random and somehow this managed to beat both Wood2 and Wood1 Boss and wasn’t doing so bad in Bronze. I had a problem with releasing the 5th app though.
Bronze to Silver
Implementing a next_best_app’s function for the release phase, which gave me the the lowest debt inducing project to release, and if player score was 4, it would return a list of cards needed for remaining apps.
I used this list to start moving to the appropriate desks after 4 releases, it was weirdly enough to beat the Bronze Boss
Silver to Gold
After some replays in the top ladder, I decided to implement a best move function that would, based on a manual scoring system for each possible_desks, try to get 4 CI/Bonus combo as fast as possible, then start moving to the next_best_app’s needed cards. I had to add the special moves given by “Daily Routine”.
I submitted the code after about 20 successful games against the Silver Boss, and was surprised by how well it was going, getting a score of 32 in Silver League and pushing me straight to 100~ish in Gold.
At one point, I reached 20 th in Gold after a lot of small tweaks in the best_move function, but was relegated to 40th.
Final Push was 1 minute before the end of the contest, and I decided to push because it was beating Jacek’s boss if I was the starting player quite often.
Unfortunately I couldn’t reach the Boss, but I’m pretty happy with everything, this was a very entertaining and eye-opening experience.
I hope more Events are coming! Again, TY CodinGame AND Société Générale
Arrivederci!
10 Likes
Your bot gave me a hard last night on the challenge…
I implemented a classic MCTS with golang, full 2 players game simulation, random rollouts until a win or 200 estimated rounds …
Still not happy with the way it ended , 315 silver… But it’s always good to participate to a CG challenge !
3 Likes
Why are you using byte arrays instead of regular objects with byte properties to represent the board? Will it be fast?
3 Likes
Finished #3 legend
Thanks for the fun contest! Congrats to bowwowforeach and ValGrowth on #1 and 2.
My initial bot did a full search of my first turn and scored final states with an evaluation function. If I played a CODING or TRAINING, I considered all possible sets of cards drawn, continued the search with each possible set of cards, and averaged the search value across all possible draws (with the correct probabilities). I spent some time tuning the evaluation function and testing with self play on AWS. This bot was #1 for a day or so on Monday/Tuesday. After that I stopped being able to make progress by tuning the evaluation function.
I saw Psyho mention the idea of doing rollouts to the end of the game. So I decided that I would combine my decent evaluation function with the results of rollouts to get a really good evaluation of the leaf positions of my search.
I implemented an MCTS-style one-turn search. First, I constructed the tree of possible move sequences until the end of my turn or until I played TRAINING or CODING. Then I did playouts from the root, choosing edges with UCT until I hit a leaf (that is, turn end or TRAINING/CODING). Then I did two things:
- do a static evaluation of the leaf. (If the leaf is a CODING/TRAINING, evaluate it like before: for each possible set of cards drawn, recursively search to the end of the turn and find the best possible static evaluation score, then average those scores over the draws).
- do a rollout from that leaf until the end of the game using a relatively cheap heuristic policy for both players.
The overall score of the playout was then 1/-1/0 for win/loss/draw, plus k * (static evaluation of the leaf). I used the 50ms to do as many playouts as possible and then selected the move at the root with the highest average playout score.
I found that the rollout scores became more accurate than my static evaluations as I got closer to the end of the game. So k starts out big, so we pay more attention to static evaluation and less attention to rollouts. Then as the players release apps I decrease k. When someone reaches 4 apps I set k=0 and rely entirely on the rollouts.
At the beginning of the game I could do about 1700 playouts in 50ms, increasing as I got closer to the end of the game.
One thing I noticed was that the rollouts were much smarter than my evaluation function at figuring out what apps to release to block the opponent. Like they could tell when it was absolutely necessary to release a certain app and take 5 debt so that they opponent couldn’t use that app as their 5th. Before adding the rollouts my bot had been quite debt-averse, but after adding rollouts it starting taking on lots of debt when necessary, like many other top bots do.
The improvements I got from here were from improving the rollout policy. I used a deterministic policy, but properly simulated randomness in what cards players would draw. I started each rollout assuming the opponent’s entire deck was in their draw pile, then correctly simulated draw/hand/discard dynamics from there.
I tried to make the rollout policy a decent player in its own right, and spent some time playing the rollout policy against strong bots in the IDE. One thing that I found pretty important was putting a bunch of logic in the rollout policy to find instant wins once it reached a score of 4. I think this made the bot smart about understanding what situations were especially dangerous or advantageous. For example if the opponent has 4 automated bonus and 1 automated REFACTORING, it’s very dangerous to leave any REFACTORING apps available because it gives the opponent an instant win once they reach score 4.
25 Likes
I’ve wrote something about that here.
I’ve just added a post which might contain an answer. It contains a link to a really interesting video about java performance…
4 Likes
#1 legend
I used MCTS.
Search
- Nodes do not have states.
States are computed while selecting nodes in the MCTS selection process.
Uncertain information is determined randomly ⇒ The same node has a different state each time it is passed.
The next node is selected from the nodes that are legal at that point. - Playout is terminated after 6 turns (MOVE to RELEASE as one turn) and judged by the evaluation function.
Evaluation function
- Actual score in the game
- More skill cards are better
- More CONTINUOUS_INTEGRATION cards are better
- Less debt is better
- More persistence effects are better
- App Rating
Better if it’s in reach
The state in which 4 out of 8 skills required for application release can be automated is called “Reach” state. When in Reach state, one card in hand plus one card picked up after the move can be released with 0 debt.
It is good if the cards needed for the release are present in the deck. - Final Release Evaluation
When 4 apps have already been released, the higher the probability of drawing a card needed to release an app in reach state, the better. If none of the cards are in the deck, points are deducted slightly.
Pruning branches for action
- The first move was either CONTINUOUS_INTEGRATION or DAILY_ROUTINE.
- When score=4, the player should search all the moves until the RELEASE phase and if there is a move that is sure to win, he or she should always choose it.
- No application with more than 5 debts when released is allowed to be released.
However, when your score is 3 or more or your opposing score is 4, there is no limit.
When your score is 3 or higher: The 4th release may have more debt in order to save the 5th release for an app with less debt.
When opposing score is 4: Ignore the debt in order to sabotage the opponent’s final release app by releasing it first - Prohibit movement to the location to GIVE in the early stages of the game.
- DAILY_ROUTINE is limited to 2.
- Automation of the same basic skill is limited to 2.
It was an interesting game that I had never played before. I learned new ways to search.
Thank you very much.
31 Likes
7th Legend
I did a full simulation of my turn with a classical evaluation. The original point was to decide which app to complete. I computed the average hand regarding my hand and the opponent hand, leading to an average number of debts for each player and each application. Based on that, I applied weights to the different applications. It means I accept to take a little more debts to take an application which is good for the opponent or to let an interesting one for my 5th.
It was nice to have a deck building game for challenge even if I regret that any other strategy than CI seemed to be worth.
15 Likes
Legend 2nd
【Before the Legend League is opened】
A rule-based AI composed of many if statements and my human senses.
This rule-based bot was in the 5th-10th place in the Gold League (before opening legend league).
- BEGINNING MOVES
The first move is hard coded. Until the middle of the contest, I used to first DAILY_ROUTINE. Later changed to the first CONTINUOUS_INTEGRATION.
- MOVE_PHASE
Even in move phase, think about the technical debt number for release an application at the release phase in this turn. Calculating the minimum amount of technical debt I will receive if I release any application, and move so.
However, I set restrictions on the release of applications. As shown in the image below.
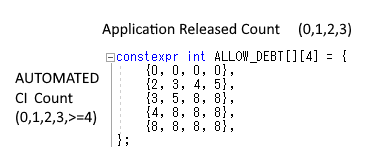
For example, 2 applications are released (=my score is 2) and 1 CI is automated, I allow to receive 4 technical debt when releasing.
If these conditions are not satisfied, I will not release the application. In that case, move to closest location that has a card required by any applications.
- THROW_PHASE
The thinking routine is independent of MOVE_PHASE.
Throw the card with the least number of sum requirements in all applications.
(Sometimes my bot throw away the bonus card, but I don’t understand why he do so because my source code is messed up  )
)
- GIVE_PHASE
Same as throw phase.
- PLAY_CARD_PHASE
If I can release an APPLICATION under the conditions shown as image in MOVE_PHASE, use only the card if the number of technical debts I will receive in release phase does not increase. However, I regardless use CONTINUOUS_INTEGRATION for BONUS and CODE_REVIEW because they are powerful.
- RELASE_PHASE
Release an application that makes minimum technical debt.
Again, the decision to release or not is as shown in the MOVE_PHASE image.
【After the Legend League is opened】
MCTS including opponent’s actions and random card draws.
As a playout player, I have used the rule-based bot introduced above (This was very effective than random playout).
I didn’t use any evaluation functions.
As a feature, each node does not have GameState, only has Actions for each children nodes. Every time in iterate MCTS, I built the game state from the root game state of the root node. Therefore, the same node may have different game states because of random card draws, but it does not make any problems (at least as far as I can think).
This allows you to explore deeper because it does not have branching by random card draws.
This bot got 1st place the day after the opening of the Legend League
After that I tried various improvements to this MCTS, but none of them worked.
For example, “using UCB1 Tuned” or “expanding all child nodes at once and select best one” or “improving my artistic spaghetti rule-based bot” was all make not sense.
In the end of the contest, this bot got 2nd place in the Legend League.
Last but not least, thank you for this nice contest, I had a so much fun 
25 Likes
Rank: 16th Legend
Language: C++
First, it was a very nice occasion to commit whole 11 days to a CodinGame contest. I once reached 1st place on the 9th day, which was a great experience. Thanks CodinGame and Société Générale for hosting the contest!
I used a combination of brute-force-like search and linear evaluation function which is learned by reinforcement learning.
While many other participants applied heuristic “rule-based” choices (like one in MCTS), the parameters on my evaluation function was completely detemined by a computer program.
Overall Strategy
First of all, the important point of this game is that:
- The chain of actions from MOVE to RELEASE differs so much by slight difference of one choice or slight difference of one card. It is very “discrete” in this sense.
- However, when the next player draws 4 cards, it will be smoothed out. It is true that there are lucky draws and unlucky draws, and one difference of drawn cards will change everything. But in the sense of expected win-rate, all possibilities are condensed, taken average, and becomes “continuous”.
I thought that the contrast of discreteness and continuousness was the key to the problem. This trait gave me the insight that:
- We need to brute-force (or search like MCTS) chains of actions from MOVE to RELEASE, to find the best action, because evaluation can be difficult.
- But it can be easy to evaluate “terminal phases”, which are the phases after RELEASE and before drawing 4 cards.
This became the blueprint of my algorithm for this game. Then, all I need to do is to make the brute-force-like search algorithm and a good evaluation function of terminal phases.
Part 1. Search
In fact, the number of chains of actions from MOVE to RELEASE is not so large. For example, there are about 200 chains of actions on the first turn (one of them is MOVE 5 → CI 8 → WAIT).
It turned out that we can search about 10,000 chains of actions in 50ms time limit. So, brute-forcing them is possible and can find the “true” best-evaluated action.
If there are many TRAININGs and CODINGs, many branches will occur and the number of states to be considered will increase exponentially, which may exceed 10,000. For coping with such cases, I used the following search algorithm.
- Until reaching terminal phases, repeat choosing an action randomly among which the next state is not “everything is searched”.
- If the state become “everything is searched”, the true evaluation is calculated so we don’t need to search all states. Otherwise, we calculate the evaluation based on searched results.
- If the root state become “everything is searched”, it means we completed the brute-force and we can quit searching.
This algorithm enables to brute-force (or nearly brute-force when the number of states is large). The reason why I did not use MCTS here and applied almost-pure Monte Carlo choice is the “discreteness” of this phase.
Part 2. Evaluation Function
As the terminal phases has “continuous” traits, I thought that the win-rate can be predicted by an easy formula. For example, we can imagine something like the following:
- One technical debt decreases win-rate by 3%.
- One automation of bonus card increases win-rate by 20%.
- A person who is at location 0 is favored to win by 15% against the person who is at location 7.
So, what can be done in general? The game states can be divided to many components - score, location, the number of each cards, the number of each cards automated, the skill levels, and so on. I tried to assign “advantage weights” for each components.
Let’s go in details. Suppose the advantage weight of one automated bonus card is 1.1. If a player has 5 bonus and the other has 2 bonus, the player has +3.3 advantage, which is translated by 1/(1+exp(-3.3)) = 96.4%.
In general, I intuitively used logistic function to translate the advantages to win-rate (like chess). Let (w1, w2, …, wk) be the advantage weights of each component, and (x1, x2, …, xk) and (y1, y2, …, yk) be the values of components for each player, the advantage is calculated by A = w1(x1-y1) + w2(x2-y2) + … + wk(xk-yk), which is translated to win-rate 1/(1+exp(-A)).
Part 3. Machine Learning
I used TD-learning to assign the advantage weights. 20,000 self-plays were done using the epsilon-greedy method (70% optimal choice, 30% random choice).
The “temporal difference” in TD-learning is the difference between the estimated win-rate using pure evaluation and the estimated win-rate using brute-force-like search towards the next terminal phases.
One self-play took about 100 turns on average and took about ~0.2 seconds in the end. Overall, the 20,000 self-plays were done in about 2 hours using a single thread of Intel Pentium Silver N5000 CPU (1.1 - 2.7 GHz).
How the AI learned to play?
At first, all advantages weights are set to zero. So, everything was random-like at first dozens of games.
At about 1,000 games, the AI learns the efficiency of “CI 8” and the first player becomes likely to win (like 70%). However, at about 5,000 games, the second player knows to “MOVE 2 → DAILY_ROUTINE” at the first turn, then the win-rate becomes even against first player and second player.
Gradually, the AI knows the efficiency of CI-ing normal cards and the knowledge of locations, and became more faster to finish the games.
The Advantage Weights
Some part of calculated advantage weights (for the first player) are given below.
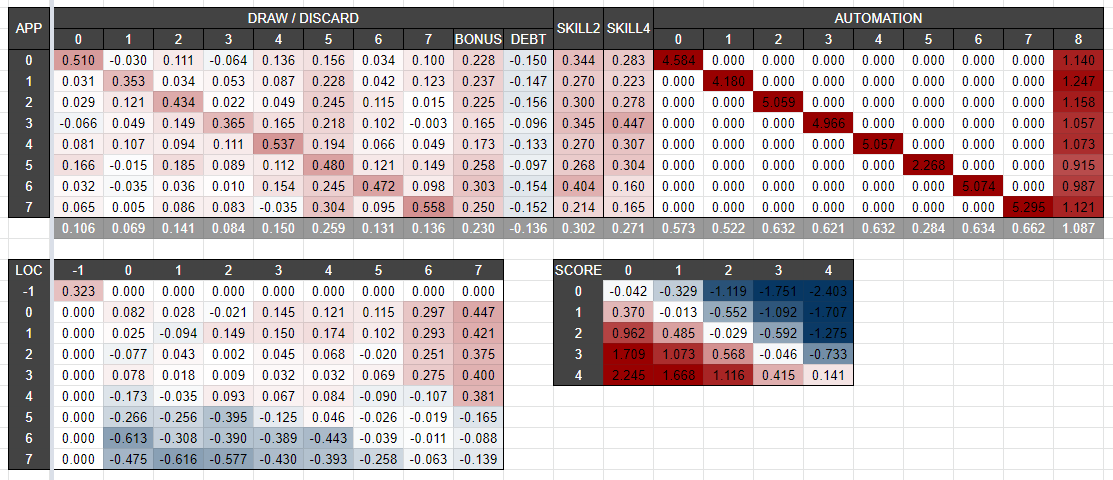
I think that this yields some lessons for this game. For example:
- One bonus card increases ~5% win-rate.
- One technical debt decreases ~3% win-rate.
- The strength of cards are 5 > BONUS >>> 4 = 2 = 7 = 6 > 0 > 3 > 1 >>> TECHNICAL_DEBT.
- One automation of bonus card increases ~20% win-rate.
- One automation of normal card (except 5) may increase a decent win-rate, depending on required skills in the remaining apps.
- When the turn begins (and before MOVE), “player is in location 7 and opponent is in location 1” is the worst, while “player is in location 0-4 and opponent is in location 7” are the best.
- The fact “player’s score is 4 and opponent’s score is 0” increases ~50% win-rate just by alone.
Finally, this was really an interesting game to tackle. Thanks!
21 Likes
11th, Legend
My approach was almost the same as @_Royale except for the draw part. I only simulate the biggest probability branch. I don’t have much information to tell unfortunately, and this PM is just for counting the number of machine learning approaches.
Thank you very much to organizers, sponsors and especially @_SG_Sebastien for holding this contest. I love bot programming contest, and I hope more contests will come.
11 Likes
Used a similar but more novice approach (NN trained by GA) to rediscover that area. How did you encode your weights to keep the code under 100k? I had to quantize them on 1 byte and craft a weird char2int func to load them in CG (although I could have done with 2 bytes on my end with about 35k weights, spent my focus elsewhere). How much possible values were enough?
Most unicode (utf-16?) characters are counted as one, up to around 55k, so you can have almost int16 per one character. I use them to convert back and from lowered-precision (almost 16bit) float. This way i can have 1 weight 1 character. My encoded weights look like this:
wstring weights = L"旔昰柽昪崦圲圌圄囜坏圓圱圴圦地…";
I see, reassured I was on the right track then with my “-a~qetM/#r+QJt8nA@…” weights. Thanks for the info and the unicode trick!
1 Like