You might want to have a look here; Public API for statistics or other useful things
Given the id of a game, “services/gameResultRemoteService/findByGameId” sends you the JSON of the replay.
Inspect->Network can help you finding more APIs.
IIRC it is a greyish area though.
4 Likes
Thank you [LOCM]aCat, radekmie and CodinGame for these two contests.
RUSH
I loved this format.
[CG]Thibaud already explained the issues on the blog so I am sure we will have ever more fun in the future.
We had the referee which was helpful if you are familiar with the CodinGame SDK since you could make local simulations even when the platform was down, but I lost some time because pom.xml was missing, not sure if this was intentional.
During the draft I would PICK the first creature available, or PASS.
I did a Monte Carlo playing random moves (SUMMON, ATTACK) for myself only. I only handled GUARD and CHARGE.
My evaluation function was:
- INFINITY if opponent is dead
- sum of my minions attack
- sum of opponent minions attack
- opponent health
This code finished the RUSH in 8th position.
Everything below is related to the marathon.
REFEREE
Starting a new contest, I like to convert the Java referee to C++, including the initReferee() code.
Then I write a dummy bot that do random moves with a fixed seed and hashes the inputs.
Having done this, you can compare the results of a game in the CodinGame IDE and in the local simulation with the same referee seed to be sure you have a complete and bug free simulation.
I do theses tests every time I modify my bot, so I can be sure any modifications or optimizations I made did not break the simulation engine.
I keep everything in one big file, that will either compile as a referee, dummy bot or my arena bot with a bunch of #ifdefs.
SEARCH ALGORITHM
The referee included the computeLegalActions() function that was very helpful.
I did a Monte Carlo at depth 2:
- play random moves for myself until I PASS
- play several random responses for the opponent using the same approach
- keep the worst score after my opponent response
- stop as soon as it is worse than my best move so far (pruning)
EVAL
+/- INFINITY if a player is dead
+/- sum of player creatures scores
+/- CARDS_DRAWN_MALUS * cards drawn
+/- player health
CARDS_DRAWN_MALUS was to avoid attacking the player if it breaks a rune and allows him to draw an extra card.
My final push had a quite high value meaning I would not attack the player if I break a rune unless I deal a lot of damage.
For the creatures on board scoring, I used a multiplicative evaluation:
BASE_CREATURE_VALUE + CONSTANT * (keywords.hasLethal + pow(attack, A)) * (keywords.hasWard + pow(defense, B));
Where A < 1 and B < 1.
BASE_CREATURE_VALUE was to give a minimum score to a creature, even if it had no attack or poor value since it could be upgraded.
My idea with the multiplicative evaluation was to favor cards with balanced attack / defense. I would prefer a 3/3 creature over a 5/1 or 1/5 creature.
If it has lethal then defense is more important since you might kill several creatures with it.
If it has ward then attack is more important since you basically have a free attack.
All the other properties were ignored because I could not find any good valuation for them.
DRAFT
Since I could not find anything good (see below) I ended up looking for my opponents preferences in the arena.
Each card had a static score, with a 2 slot mana curve (small cards vs big cards).
After each PICK, the scoring was adjusted to avoid having only small or only big cards.
LOCAL SIMULATIONS
In order to adjust the parameters for my bot, and since I am not patient enough to wait for the IDE or the arena to complete, I like to rely on local simulations.
This can lead to inbreeding on some contest (where your bot is very good at beating himself, but poor in the arena) but in my personal experience it performed pretty well on this contest.
Since the game was pretty unbalanced, you had to run a lot of simulations to have a decent result (I did 1000 games as player 1 and 1000 games as player 2 against my best bot so far).
Basically it is cg-brutaltester but using GNU Parallel and my local referee.
JUST FOR FUN
During week 2 or week 3, I did a small web interface to play against my bot.
It did not help but it was fun (unless you are player 2  ).
).
Basically it was a modified bot who was responding to AJAX requests to update the display or get human’s inputs.
WHAT DID NOT WORK FOR ME
- Mana Curve: in Hearthstone they always talk about this so I tried to have a balanced deck with cards for each turn. In the end I had a 2 slot mana curve with felt dumb but worked better for me.
- Before the Monte Carlo, I started with an iterative beam search depth 2 (doing plays for me and the opponent considering the N most promising moves). This performed worse than Monte Carlo, probably because I did not do the alpha/beta pruning correctly.
- Most played draft: doing local simulation where each bot picks random cards, and keep the most played cards. This ended up having mostly small cards because or early wins.
- Genetic draft: start with a pool of random scores for the cards, and after several simulations use a genetic algorithm to refine the scores. This was slow and the resulting deck was bad…
- Hand value: try to keep items in hand to avoid using them poorly. Unfortunately, my final bot would accept using “Decimate” (-99) on a 1/1 creature since if it would end up on a better board scoring.
CONCLUSION
The game was pretty unbalanced and had too much randomness and hidden information as reported by other players.
However ClosetAI was in 1st position for a lot of time until the end, so I guess we all had space to improve.
But I think 4 weeks was too long, I prefer the 10 days format, and it seems ClosetAI pretty much solved the game in the first week…
21 Likes
Final Position: #11
Feedback
This game is amazing… No bad thing to talk about, I loved it.
Great job @[LOCM]aCat and @radekmie
- No Bugs
- Clear Rules and Statements (I didn’t need to read the referee to understand things)
- Very good visual interface
- No complicated phisics
- The cards are balanced. At any card games, there are more powerful card than another, it make the choices more important. And card power is subjective, I think that Ward is better than Lethal in general.
- The red side advantage is not a problem, since we have mirror match with same seed.
Strategy
Wood to Bronze
I always try to pass wood leagues ASAP. My strategy was get the lowest card at the draft and always summon and hit face (or guard), without any kind of simulation or evaluation, just do it…
Bronze
First, I got the card list, and set a score for each card, manually. I play Hearsthone since its launch. So, with my experience I could build a decent card score list, and fit it to a mana curve.
I was the #1 for some days during bronze, because my draft was good at that time, and I had a decent eval function.
Silver
Here my problem started, a lot of people was building better AI than me. My manual tunning was not working very well.
I noticed that my simulation strategy was not good, so I change my simulation to a Monte Carlo if the command list is too big. If not, I eval all possible moves.
Gold
As my AI was not improving with manual changes, I tried to build a formula to score the cards at draft, and then auto evaluate all my magic number.
At this moment I had 95 magic number:
- 31 to evaluate the card
- 19 to evaluate the mana curve adaptation
- 45 to evaluate the board
I rent some server to play against myself thousands of times, with a genetic algo, to find the appropriate magic number.
Such a waste of time and money, I spend $30 in servers to try to eval this number, but it is too many number, and the result do not improve my gameplay. But I still got legend with this algo…
At this time, I had 2 codes, one for red side, and another for blue side, and all magic numbers was different for each side. But, at the end, I keep only the draft score different for each side.
Legend
Time to rebuild.
Mana curve adaptation was not working, so I removed it.
I corrected a bug that spend blue cards on the opponent face. Blue card only go face for lethal damage.
The formula to score the card at draft was not working, so I back to score it manually, I build a script to download all games from a player, and try to identify the pick priority using a true skill algo, and others stuffs. I started getting @MSmits draft priority, and then, I got the @euler draft priority, that works better for my eval function.
My eval function was very, very, very complex, and it was very confusing…
At this time, @blasterpoard wrote his eval function at the chat, without the magic number:
- HP = defence + (hasWard ? X1)
- DMG = max(attack, (hasLethal, X2)
- SCORE = X3 * HP + X4 * DMG + X5 * sqrt(HP*DMG)
Time to back to my genetic algorithm, I rewrite my eval, and rent more servers to find good number for this 5 parameters… And I found it.
All of this was at early days at the legend league, during the last five days, I was watching games, and tunning it manually, and then, I realize that top player have some kind of dynamic score for draft… So these days I was looking for a way to add this kind of behavior, and I did it, not trying to adapt to a mana curve, but trying to avoid extremes behaviors:
- If I have more than 4 cards that cost 7 or more mana, reduce 10% of the score for big cards
- If I have more than 8 spells, reduce 10% of the spells score
- If I have more than 12 minions that cost 2 or less, reduce 10% of score
- Each time that I pick a card, reduce 1% of this card score
- If there is too many lethals, increase the score of ward cards
- If I have less than 2 cards with draw, increase the score, if I have more than 4 decrease
- And some others smaller stuffs
At the final day, I had a 12 magic numbers at my eval function, so, I run the final GA to find better numbers, and after 100k games, I got it… I jump from #25 to #10 after it this tunning…
Curious things about my code:
- I did 700 submitions
- I eval my life as a negative score, because when you do damage to yourself you can buy more cards, and cards is better than life, if you will not die.
- If enemy creatures that left at the board deal all damage to my face, and the result is a final health of 4 or less, I apply a negative score, because there is a lot of cards that can do 4 damage to face, so, I have a great chance to be dead next turn…
- I have different patterns to evaluate the cards at my hand, at my board and at enemy board
- I play MC search for 70% of the time for my board moves, and the other 30% of the time, I play my best 5 scores as the enemy. For this, I keep the best score that clear the enemy board, and the others 3 best scores that do not is equal…
- When I implemented the runes behavior to check if I have lethal damage, my rank improved a lot. I track the opponent board, to check if he play some card that gives draw, and how many cards he will draw after my attacks, so, I can identify if he will be out of cards… At high rank, you can’t lose a lethal damage.
What do not work for me
- Try to fit a mana curve
- A formula to evaluate the card at the draft
- A score to evaluate the card at the draft (For the draft, I use card order only)
- Different evaluation functions for each side (Red and Blue)
- Give my cards to opponent to eval the opponent turn
- Deep two evaluation (My java code can simulate only 10k actions, so, I even have performance to do it)
What I think that can be improved
- Draft: There is a lot of things that can be done. Mainly based on statistics
- Hard Coded some situations that eval think that is better, but it is not… Sometimes my AI exchange a lethal minion at a ward. Or buff a minion that will die to a lethal anyway…
- Have different eval function for each stage at the game (early, mid or late)
- Identify when you will be out of cards faster than your opponent and play more agressive
- Identify when your opponent will be out of cards faster than you, so, you can play more passive
- Deep 2 simulation… You should play different if you have green/red cards at your hand to next turn. For example, if you have some greens, it is important that you have more minions at board to buff one at next turn… If you dont have, you can play only one fat minion
- Predict enemy spells and what is the impact of each one…
Conclusion
This game is very addictive, and this T-Shirt cost me $100 dollars, the most expensive T-Shirt of my life!
16 Likes
17th
My bot uses a minimax, where the moves are generated randomly instead of doing a full search.
The draft uses the card orderings for ClosetAI and reCurse.
Not sure if it’s even worth writing this.
Draft
Mid-contest I analyzed the draft of some bots. They had a fixed order and would always pick the same card, ignoring a manacurve.
So I used the ordering of ClosetAI and reCurse and combined them: you have to play more aggressive as player 2 and try to rush your opponent.
If both orderings tell me to take different cards, I tend to the cheaper one as player 2, the more expensive one as player 1. I also allow to go back a few spots in the ordering, if it fits better to the manacurve.
Battle
I generate random moves for myself to summon cards, use items and attack the opponent. I don’t have a 2nd summon phase but memorize the creatures that I tried to summon in the first stage and add them later if there are free spots on the board.
During the attack I select a random target and attack that until it’s dead or I randomly decide to stop.
For each of my own plans I test 200 random opponent reactions and assume the worst-case, just as in minimax. As I don’t know the opponent hand, I completely ignore summons (I tried to make something up, but failed).
I do some hashing not to test the same moves for myself twice (and run an expensive opponent prediction again).
After offline-testing against myself with a higher timelimit than the 100ms I get online, I decided that I don’t have to optimize my code for speed any further.
The game
The beginning was quite straight-forward: write a sim, generate moves and score the outcome. That made it easy to detect good attack orders (use breakthough last, don’t attack with two creatures if one is enough, …).
But after one week I failed to improve my bot notably. Whatever I tried offline, my winrate was close to 50-50.
I’m not quite happy with the randomness. No matter what you draft, you have no guarantee that you aren’t blocked for the first few turns as your cards are too expensive. On the long run the best bot will always win, but that requires a lot of games.
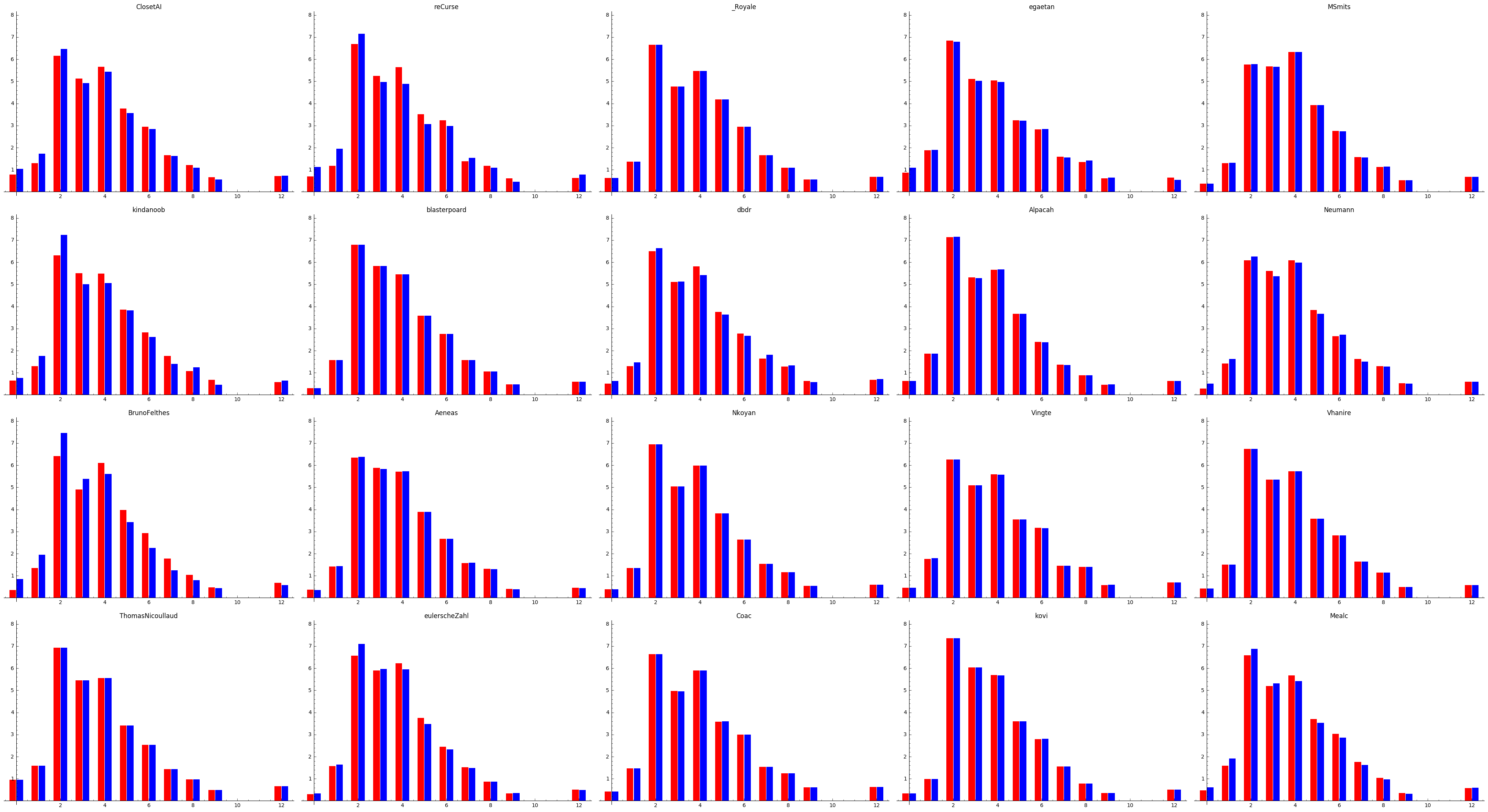
Statistics
To have at least one interesting part in this post, I made some plots of the manacurves. They aren’t totally accurate, as the last battles on the leaderboard don’t show all matches.
You can see red bars indicating the cost of the items taken as player 1 and blue bars for player 2. You can see that reCurse drafts a little more aggressive than ClosetAI for instance.
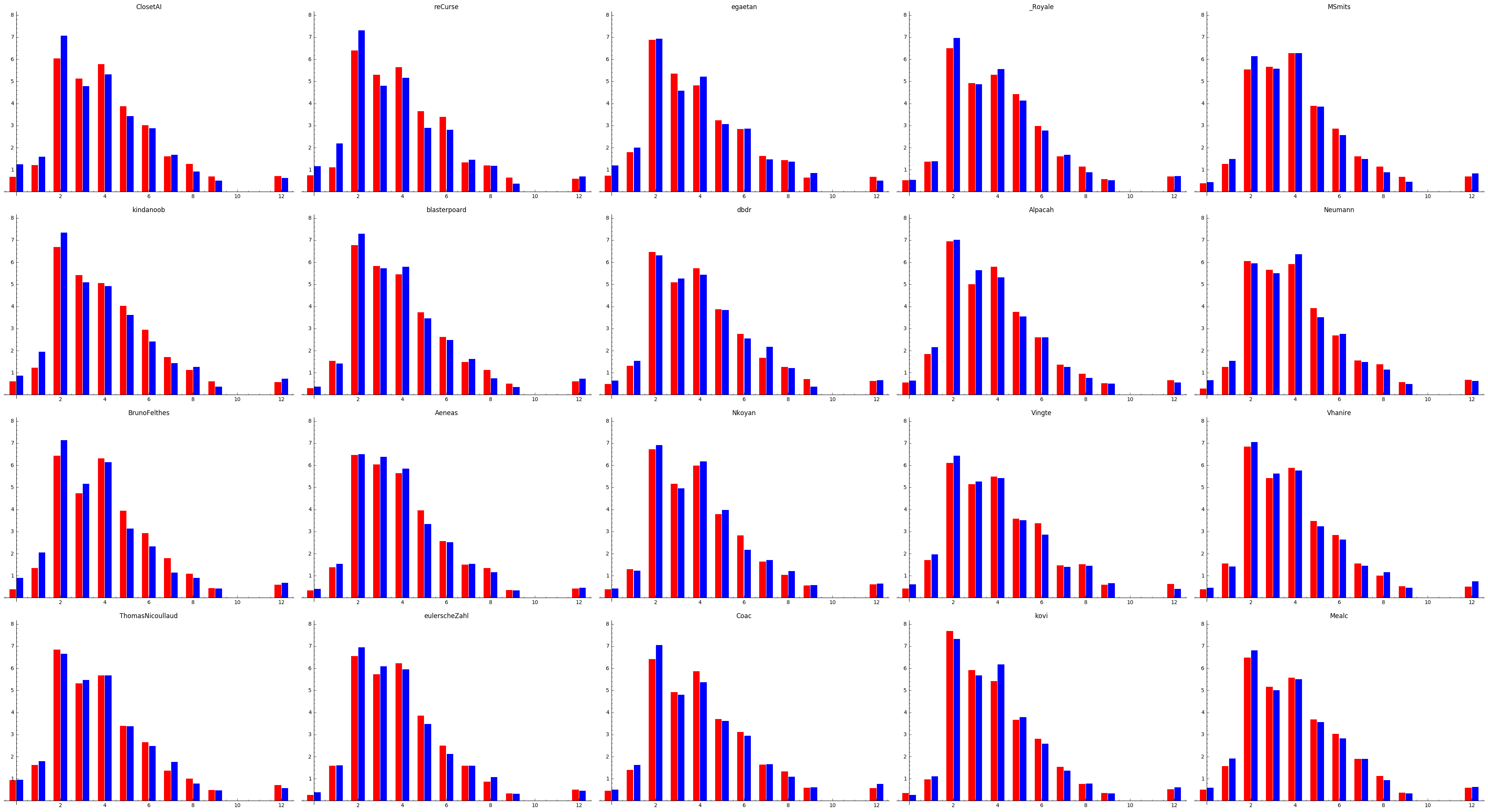
Following is the same plot again, but showing wins only. You can clearly see, that player 2 should pick low cost cards to increase the chances, as that bar is higher, even if the bot has the same draft for both positions.
14 Likes
1st place in legend
The Game
I feel like draft was more important and spent more time on that than on search which I haven’t changed after the first week. To tackle randomness I was running lots of local tests instead of using any arena tools. When testing a change running 100K games was a standard way to decide whether it is an improvement. This was how I managed to tweak every parameter very well and got significant gains by just modifying numbers without changing any code.
Draft
Each card is assigned base score depending on how good it is. What I did was simulating lots of symmetric games but putting 2 copies of given card in one of the decks and taking the winrates after 20K games or more. After multiple rounds of self play base scores will be stabilized. This process needed a few hours on my laptop, so I did it a few times overnight.
Later I added dynamic draft. Starting from 13th pick In addition to base score each card gets bonus/penalty depending on how many cards we have in corresponding slot already drafted compared to curve targets. These slots were: greens, <=1, 2, 3, 4, 5, >=6 costs. There was also a target for card draw (4 in total). There is a penalty for picking same cards as before and picking cards that have better drafted cards in the same slot.
Draft is different for two sides. For example, first player aims for one 1 cost cards but for second player aims for two.
Search
I used same 2 turn Minimax as everyone else I guess. I did “full” search by considering all plays in SUMMONS-USES-ATTACKS order and then all possible attacks from my opponent. To avoid duplicates there were a few tricks very similar to what MSmits described - sorting defenders creatures by having guard, sorting attacking creatures by attack, always attacking hero with remaining attackers if there are no guards (except when there is only 1 such attacker, in this case I consider not attacking hero).
Evaluation function is sum of creatures values, card draws and only account for player healths when they are low. In the end I also added big penalty for not having cards in decks and since I was not handling rune mechanics at all this helped quite a bit. There are also some hacks to avoid bad plays like not trading valuable creature with smaller guard one since this gives opponent more choices. There is also a small bonus for having more attack power than opponents health.
In creature evaluation health and attack are important, guard is somewhat relevant, ward adds an additional attack, for lethal evaluation function was different. Drain and breakthrough are irrelevant.
Search is usually very fast but there is a break if 10000 iterations are reached.
Thanks
To organizers for a great contest. The referee implementation was easy to follow and didn’t have bugs - there was only one small patch after the contest started. Some didn’t like randomness but in card games this can’t be avoided.
28 Likes
hi Royale
you had the time to write a small simu in the sprint contest ?
nice …
4h would be ok to do it, I guess.
Ok,for the sprint feedback ; here is mine (as the #1 french player  ) :
) :
- read quicly the statement : ok is is a card game with draft phase and play phase.
- create your class (Card / Player) and read inputs
- one line for the draft phase to order the card by creature -> attack / (cost +1) -> - cost
- one line for the summon to order the creature to summon (same formula)
- one line for the draft to order the creature to attack (same formula)
- one line for the target.
Linq is your friend.
4 lines and you have a pretty good bot for the sprint (ranked 6) which pass to silver easily and required improvment to pass to gold.
7 Likes
55th legend, (my first time in legend during a contest)
first of all I would like to thanks the authors of the game, aCat & Radekmie. it is really not easy to balance a game like this one.
I used to play Magic in my younger time, but I’ve never heard about Hearthstone or TESL before this contest.
We need a card game, we got a card game…
I was very happy to play with this game.
Most of my deceptions are about the random… In this game, there was way too much random…
the second thing is the assymmetry of the starting position.
I was not able to participate to the sprint contest due to family reason. and I started the marathon one with some delay.
to go to bronze league:
I simply use a random draft: cout << "PICK " << rand(3) << endl;
then a very simple heuristics:
- summon/use the card with the higest possible mana cost
- attack guard creature if there are one
- attack player
to go to silver league
I sort all the cards given them a unique value (a small array of 160 values) mainly base on the simple formula(atk+def)/(cost+1)but with some manual tweak.
some little improvement: the begining of a simulation to be able to eventually summon/use more than 1 card.
go on with the same attacking strategy
to gold league
REFACTORING…
I refine my draft score formula, still based on cards characteristics
I do a simulation. I done a flat Monte Carlo search over all possible actions I could made.
and spend long time to setup an evaluation function that works…
to legend League
I try to copy the draft of other players…
I simulate the opponent turn (but only his attack phase with the remaining cards)
I forced all cards on board to have an action, except card with atk=0
In my eval function I looked at taugth minions 5*(ATK+DEF+0.1characteristics)
I looked at card score 1cardscore (the same score used for draft)
I looked at card cost 5*cost
with a ‘+’ for mine and ‘-’ for opponnent.
When I tried to look at players’ hp, I drop in the ranking…
after that I tried many other thing but the good old code was better…
Many thanks to reCurse for his very helpful streams that have recall me many thing I forget about the organization of object oriented programing, and for his trick of the bitstream… since I could debug locally with a step-by-step debugger I found and solve lots of bugs very quickly!
Many thanks to Neumann, for his CGBenchmark tools and the help he gave me to be able to make it work proprerly!
Thanks also to Magus for the CGBrutalTester tool and CounterBalance for the prebuilt version of the referee (since I not familiar with the java “world” to have ready-to-use tools was very good for me)
7 Likes
Final position: #9
#Feedback
I will only talk about marathon phase because unfortunately I couldn’t participate in the sprint phase. (may be considerate the fact of a 24h/48h sprint for time zone balance like someone said in the chat)
This contest was awesome and all I have to blame is the too long time for a such contest; during the last two weeks I did only parameter tweaks and it was kind of boring.
#Draft phase
I started with a card scoring according to their stats/abilities and a mana curve, this allowed me to keep my rank in the top 20 on the first/second week, but it rapidly became inefficient.
In fact, the power of a card is way more complex than a linear combination of its abilities and stats.
Then I had the idea to bench statistics about how many average occurrences of each card are in a winner’s deck. I started downloading a lot of replays (may be too much? https://prnt.sc/kmp49w) using simple unofficial API based python script. Another script were parsing all replays and was incrementing the counter of each card when they were in the winner’s deck.
It worked like a charm and get me in the top 10 for a while!
#Fight
I started with a brute-force solution, but rapidly switched to a MC because I was coding in Python3 at this time and I lacked performances.
Then I moved to C++ for improving performances, but even with MUCH MORE combos simulated it didn’t change anything. That was the first time I used C++ in a contest, thanks to the chat for the help by the way!
#Conclusion
I really liked LOCAM and I had a really good time on both the game and the French chat!
8 Likes
#73 in Legend, #2 in C, which is nice.
Big thank you to aCat, radekmie and the CG team for this awesome contest that got me back to CG.
Feedback
I really loved this game, a couple points that stood out for me were:
- The one month format. I wouldn’t have participated on a 1-week contest
- It was the first contest I participated in where actions are not played simultaneously for both players, which was very refreshing.
- The rules were extremely simple to implement.
- Language performances didn’t matter much.
Most of it has already be said, but here is what I would like to see in the MP game:
- Provide the list of cards that have been played by the opponent.
- Some form of bonus for player 2.
- A more visible effect in the UI far which cards can/cannot attack & which player’s turn it is.
- More cards!
Intro
I’ve never played with Neural Networks before this contest, but it’s something I’ve wanted to do for a long time. This contest seemed like a good opportinity since the number of inputs and ouputs is relatively small, so i went for it.
I used the keras module to train my models locally, and Q-learning to define the output to fit my models on.
I went to legend with a Python2 bot, and switched to C during the last week for better perfomances (which ended up changing nothing to my ranking despite going from 5 to 5000 simulations per turn…).
Draft phase
I used a first NN to evaluate the fitness of a card in a given deck of card, so I would get three fitnesses at every turn, and pick the card that maximizes my fitness.
Here is the network topology:
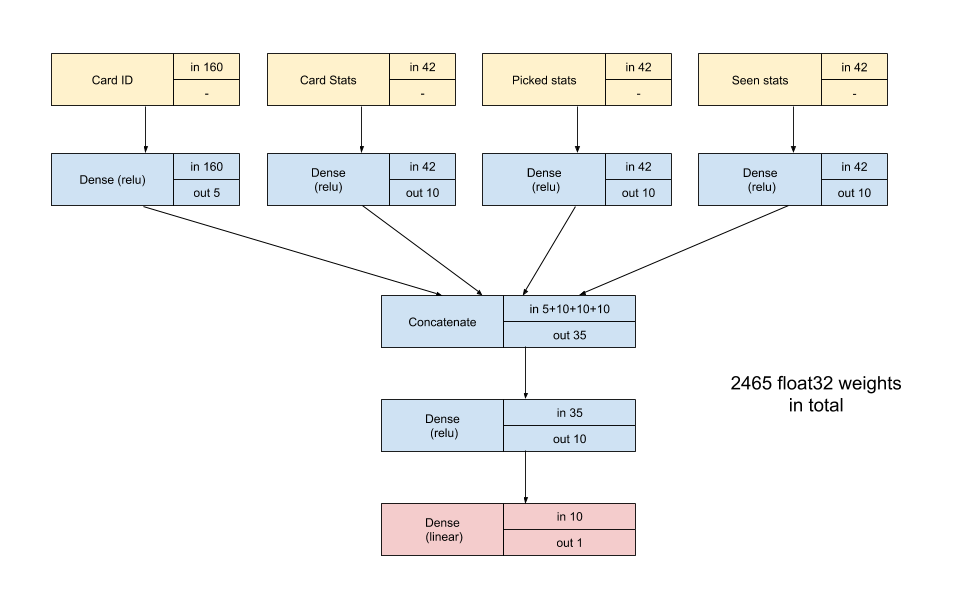
“Picked Stats” are the average stats of the card I picked previously, and “Seen stats” are the average stats of the cards I have been presented to during the draw phase so far.
To train the model, I ran games locally, and gave a reward of:
- +10 for cards picked by the winning player
- -10 for cards picked by the losing player
- -10 for cards not picked by the winning player
- +10 for cards not picked by the losing player
After ~100 batches of 500 games, I converged to a draft fairly similar to the rest of the legend players.
Duel phase
I used a second NN as my eval function, and like most here I ran a depth 2 minimax with randomly generated actions for both players.
Here is the second network (I hope you have good eyes):
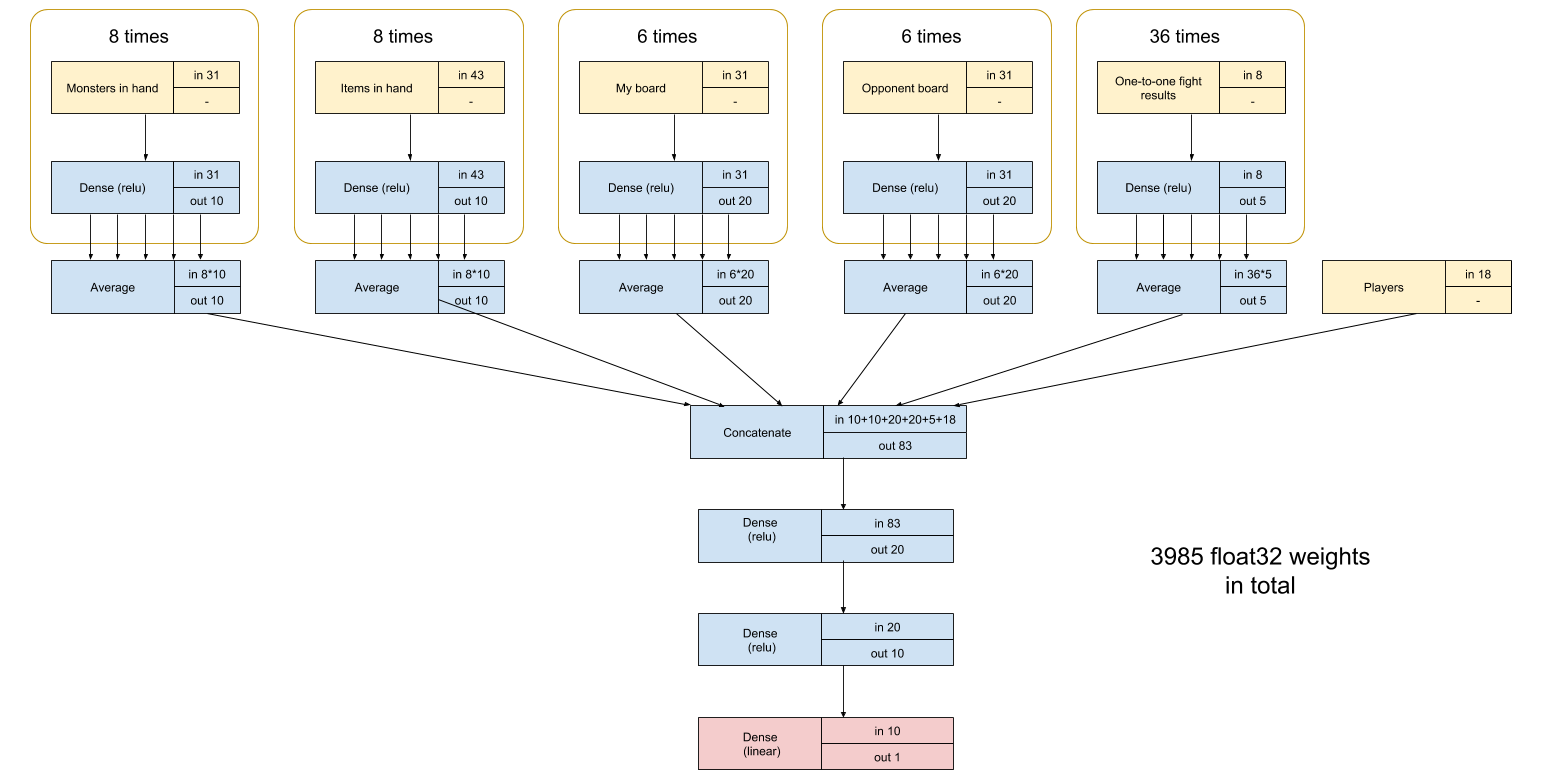
I reduced the number of weights by cutting the state of the game into a large number of small inputs, and using the same layer weights for all inputs of the same type.
So for instance, for creatures on my board I average of the output of the same fully connected layer applied to the 6 slots of my board (with zeros for empty board slots).
To train the model, I used the following formulas:
- Reward = 10 if the player has just won, -10 if he has just lost, else 0
- target_fitness = reward + gamma*next_turn_fitness + (1-gamma)*current_fitness
- gamma = 0.7
- probability to make a random action (epsilon) = 100% during the first batch, slowly decreasing towards 5%
- learning rate high at the beginning, slowly decreasing
Here is a breakdown of learning process:

During the first batch, predicted fitnesses are random, and the model only learns what a winning and losing turn look like.
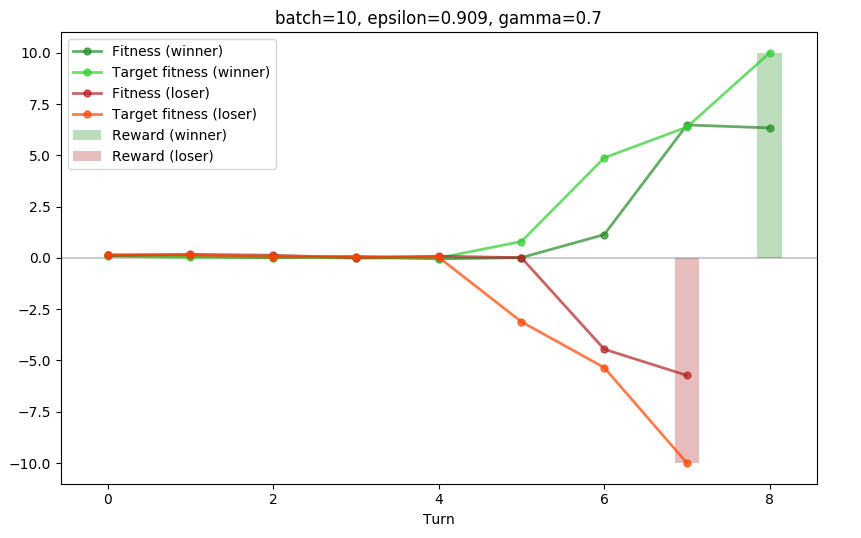
After 10 batches, the bot is still unable to figure out what a good state is at the beginning of the game, but the reward is slowly back-propagating.

After 100 batches, the bots start to have a good idea of how good their situation is at any point of the game.
Overall the predicted fitness is not that good, given my final ranking. I’ve had a really hard time figuring out all the meta-parameters in keras (and I don’t think I’ve got them right yet), I suffered a from poor understanding of NN and Qlearing during the first few weeks of the contest, and I think it’s not too good to have a bot only play itself.
However, it was a lot of fun, and I’m glad I’ve learned new things!
Oh and if you’re wondering, my bot weighs 97.1kb, not even close to the 100kb limit 
28 Likes
I’ll stay short in this post and if needed I’ll write more details later if I have time and/or someone asks for it. Many thanks to Codingame and the game creators for all the nice work done.
Sprint
I could not participate to the sprint but I think it was a great idea. It would be nice to remake sprints before some of the nexts contests if the game mechanics allows it. It would be nice to have other sprints in the future, in addition to the “regular” contests.
Marathon
I started this contest thinking I would not have a lot of time, but 4 weeks seemed enough for me to join and have fun. Here are a few points regarding the contest length :
- 4 weeks is very long, and I don’t think it’s a good idea in general.
- 4 weeks in August was a very good idea since most of us have other stuff to do during summer.
About the game in itself :
- It was very fun, easy to understand with only very few unclear statements. The design was very nice and clear. I loved it.
- It would have been nice to get more information such as the card drawn and played by the opponent.
- This game was not very well adapted for a 4-week contest, but this is quite hard to know before trying. It would have been perfect for a 10-day contest.
- The main problem for me was the difference between player 1 and 2. I think that this is the cause of many other problems, like the random ranking and the difficulty of testing new ideas. It is very hard and unstable to differenciate two players if most of the time they draw due to unfair starting positions.
Anyway I enjoyed this game and hope next contests will be as fun as this one.
Strategy
My draft was almost the same than others in the top Legend, I just gave fixed weights to each card with high values for cards with draw, lethal, ward, guard and items.
For the battle phase, I used a MCTS on the next three turns (my turn, opponent, my next turn). It was hard to see any difference with a 2-turn MCTS, but it seemed more logical to me since it is always good to have an idea of your next turn on this kind of game.
My simulations were completely random, and I picked the most promising nodes of my tree using the UCT formula (https://en.wikipedia.org/wiki/Monte_Carlo_tree_search). During the last days of the contest I introduced the RAVE formula in my node selection (http://www.cs.utexas.edu/~pstone/Courses/394Rspring13/resources/mcrave.pdf) to choose in priority moves that seem to be relevant instead of only moves for which the simulation gave good results.
The board evaluation is quite similar to what has been said with other random numbers.
Finally I finished #14 which was approximately my initial goal, I spent much more time than expected at the beginning, and I had a really good time fixing my bugs and trying things that do not work. Again, thanks to everybody involved in this contest !
8 Likes
POST MORTEM
#12 - Python3
It’s my first contest, and first post mortem. I realize there can be improvements in the following post. If you have commentaries to make, I’ll gladly read and answer you
Table of content:

![]()





11 Likes
most topics are already covered, so sorry for the repeats
game:
-the basic game setup is great (i play HS a lot) with excellent presentation and bugfree implementation. besides the discussed issues (randomness/p1-p2, hidden info), i somehow missed variations (so that not just trades matter) eg: aoes or control spells
sprint:
-the idea is great. but it proved to be too short with many leagues and slow advancement. with net 2 hours coding i ended up around 100 with (a+d)/c draft and some greedy summon/attack
marathon:
-4 weeks proved to be too long, but for the summer holiday it was reasonable
first two weeks (top5)
-quickly made MC with the following phases: precalculate reasonable good (=use all or most of mana) summons/item combos; pre-summon(charge)/use; attack; post summon/use
-score first included some heuristic enemy actions (eg. lethal), later i added depth 2 (minimax)
-for draft i started with a linear cost based model, then finetuned it towards efficient play. later i tried statistical evaluation, but when i saw closetai draft domination i gave up and just copied that
-still havent used blue items
finetune/testing = fail:
-with simulation code in place, i quickly set up an internal referee, but never completed it. i used it for draft assessment, without any success (as others wrote a simple statistic evalution gave too much bonus to low cost cards)
-then i turned to referee/brutaltester and after a few obstacles (eg. build, always send “pass”), i managed to make it work. only after a few days i realized the results were always random 50% (only after marathon i learned it was an early/bugged version of brutaltester)
-from then i just made real submits for testing. but as leagues became bigger, score became unpredictable
-after all of these, i just lost confidence in improving and lost half of my motivation
last two weeks (between 6-20)
-with failed testing and more limited free/coding time, i was able to improve only in a few areas
-finetuned the MC depth1 with hash and the limit(s!) for depth2 iterations (for best candidates i did excessive depth2)
-improved scoring: include draws (which also a way to avoid helping enemy draw on rune limit), include remaining hand value (eg. don’t waste too much vs. lethal or use decimate on 1/1), weaken hp (face value) above 5hp
-finetuned draft (by top players + my usage pattern), avoid too low and too high avg cost, prefer/penalize draw cards accordingly
recalc
-fell hard from 5->19, but i think the latter is more realistic (high places were usually probably lucky submits), recalc proved to be more effective than i expected
4 Likes
This is a great evaluation however I still couldn’t see a way to detect if you were player 1 or player 2 until after the draft was over. Maybe I missed something?
bool player2 = Opponent.Deck > Me.Deck;
That was added mid-contest but not updated in the statement, see this commit.
1 Like
Hi,
I finished 10th Legend
I used minmax at depth 2 with a recursive DFS to generate/simulate moves at the same time, in a similar fashion to MSmits :
##Engine
My engine operates in 4 passes :
SUMMON, USE, ATTACK_GUARDS_ONLY, ATTACK
I loop through all my cards at every pass. If the current card is eligible to the current pass (for instance, on the first pass, if the card is in my hand, I have enough mana to summon it and there is enough room on the board) I do every possible action for that card on a copy of the state and run the DFS on those copies. For SUMMON, that gives 2 possible actions :
- Do nothing, just continue the DFS on the next card
- Do a copy of the state, SUMMON that card, and continue the DFS on the state copy
For attack, that would give :
- Do nothing, just continue the DFS on the next card
- Do a copy of the state, ATTACK enemy card 1, and continue the DFS on the state copy
- Do a copy of the state, ATTACK enemy card 2, and continue the DFS on the state copy
- etc
When there no card to iterate over, I restart on the first card for the next pass. If the current pass was the last one, I evaluate the state.
That algorithm gives a single order of actions, determined by the order in which I iterate over my cards. To make sure I don’t simulate sub-optimal ATTACK sequences, I pre-sorted cards on the board :
- Lethal first, always
- Breakthrough last, always
- The rest is sorted by attack (bigger attack first)
I used alpha-beta to prune the move-tree, and was able to reach depth 2 almost every time (didn’t measured precisely, but from what I saw it’s about 99% of the time).
My engine could evaluate between 400 and 800k leaves in 97ms (1 leave = 1 sequence in which I play and the enemy plays) but most of the time it finds a solution in a few ms.
Since I didn’t have performance issues I later added a 5th ATTACK_BIS pass, which acts the same as the 4th one, just to add some more attack orders. That gave a slight improvment in winrate.
##Evaluation
The evaluation is quite similar to what other people said; a combination of board cards statistics + a small bonus for the cards in my hand. I tried evaluating runes, that didn’t work.
##Draft
I downloaded tons of replays (39k replays, 13.6gb …) and analyzed the pick phase; considering only the drafts that won, I calculated the pick-rate of each card both as P1 and P2.
I also stole ClosetAI second draft scores by downloading and analyzing his replays. With ~2k games from the leaderboard I could reconstruct a preference matrix (A is chosen over B) and used it to sort the 160 cards.
In my final version I use Closet’s draft as P1 and my custom draft as P2 from the pick-rates of the top 10.
A late feature was to apply bonus/malus on cards based on what I’ve already picked; the cards being split in 3 categories (0-3 cost, 4-6 cost, and 7+ cost). I set a minimum/max target for every single category and apply a bonus/malus scaled on the current turn (i.e. the bonus/malus is getting bigger as there remains fewer draft turns). I whish I had more time to tune those numbers.
##Conclusion
I don’t think this game was suited for a CG AI competition, especially a 4-week long one.
The missing information and the RNG made this contest a nightmare.
The balance was not the worst, but the dumbed-down mechanics removed some depth of the game; after 2 weeks it felt like there was no more room for improvment besides fine-tuning.
Besides all the whining I produced on the chat, I had some fun, so thanks aCat/radekmie.
I’m looking forward to see what the multi will be like.
9 Likes
I think you made a mistake here. I believe it should be, as per the Bellman equation:
- target_fitness = reward + gamma*next_turn_fitness
With next_turn_fitness given by the NN evaluated on the next turn’s inputs (well evaluated by a copy of the NN with older frozen parameters if you follow Deepmind’s DQN). And reward the immediate reward of that turn which is 0 every turn except on the last move.
But I’m not 100% sure because you seem to have concocted some “V learning”. You are evaluating states (V) whereas Q learning refers to evaluating action state pairs.
3 Likes
Hi ClosetAI, first of all congrats on that 1st spot !
It seems to be that most top players used your draft, or some version of it anyways, and it gave them a huge advantage. Can you or somebody else share it please ?
Thanks !
4 Likes
Alternatively, the formula could be :
target_fitness = alpha * (reward + gamma * next_turn_fitness) + (1-alpha) * current_fitness
where alpha acts as a “learning rate”.
2 Likes
Rank in Legend: #15
Rank in Python 3: #2
First of all, I thank [LOCM]aCat and radekmie for this contest! I’m Hearthstone player and this game really motivated me.
Feedback
I love sprint format even if I started the contest after the first half. I view this format like a big-clash of code, another format that I like. A problem is maybe that the contest was too short for (24h maybe better?).
On the contrary, the marathon was too long. Rapidly, players have very good algorithm for a fight phase and, on the top legend, the drafts was very similar.
Sprint strategy
With little time during the sprint, I turned to an aggressive strategy. For the draft phase, I pick the cheapest creature of the three cards. During the fight, for creature in my board, I trade guards if there are, else I go face. That’s all.
Draft
First of all, my value for each card it’s mana_curve_score + linear combination of statistics/(cost + 1). Mana_curve_score it’s just coefficient*(ideal_curve[cost] – current_curve[cost]) calculated dynamically during the draft. My ideal curve it’s inspired by my Hearthstone experience, a pseudo-gauss curve with the max in 2mana/3mana.
Once the gold rank reaches, I changed my draft for that of reCurse that debug its values for each card in its games.
Finally in Legend, I used the Codingame API to collect approximately 10k games on the top 20 to create new static values. I have on average three cards different with the players on top 20.
Battle
I simulated random moves composed of SUMMON, ATTACK and USE for my turn and 80 different enemy turns with just ATTACK, then I evaluate the solution and I keep the best solution. The biggest problem of these methods is that I can evaluate several times the same solution… To balance that, I limit my solution with a Boolean to know when I summon a creature without charge. After this moment, my moves has only SUMMON with an instance ids superior of the last creature summon and USE green item on my board for the rest of my simulation.
Evaluation
-
Infinity if opponent is dead and -10^9 + the rest of my evaluation if I’m dead (to make the best moves even if I’ve lost),
-
0,9*(sum of my creatures score)-1,1*(sum of opponent’s creatures score), a creature is most dangerous in opponent’s board than my board because the opponent’s hand is unknown and he can potentially use green items on it,
-
a creature score is 20 + linear combination of statistics. The constant is here for than two 4/4 was better than one 8/8. As the challenge has not added card with AoE, the only dangerous types of cards is hard removals (like decimate) or creature with charge+lethal,
-
0,01*(delta_hero_hp), the coefficient is low because I prefer trade and control the board instead of face (in contrary with my sprint code),
-
CONSTANT*(8-card_next_turn_for_opponent)**2) for limiting the opponent draw (caused by the runes) if opponent has a bit cards in hand. The difference between 5 cards and 7 cards is smaller than the difference between 1 cards and 3. With this, I don’t face if opponent’s hand is nearly empty (late game) and conversely in early game (theoretically).
Ideas that I tested without results
Before using the Codingame API to make my draft, I tried to use genetic algorithm to create the god-draft. I thank the authors of the brutaltester for this great tool. The result of my 16h of computing is a draft that have ~70% wins against my code top 30, but this new draft go hardly top 60. Great result but too specialized against my main code. The problem is surely my little knowledge in the field (count of population to find an acceptable solution, genetic operators to limit local solutions and fitness function), but I think this method has potential.
A problem of this contest is that we don’t know the cards played by the opponent (and the cards always in her deck and her hand). To know this information, I tried to deduce the opponent’s actions with the same algorithm that for my fight, but from the boards after my last turn and evaluating the difference with the current boards. I improved this algorithm by including directly the summons of the new instance ids on the opponent board. I got good deduction of opponent actions, even if I had some problems with Possessed Abomination (#53) and Decimate (#151) or other red items for example, but I had a much bigger problem… Even with this result, my algorithm for the fight has less time to calculate opponent’s actions that are also heavier. I finally give up this idea by lack of motivation but there is probably something to do on this side.
This contest was really nice and I learned many things about various subjects.
5 Likes
Depending on how well your bot can use different cards you may have different list and you could train your solution, but if you just want cards sorted from best to worst this was my list at some point:
116 68 151 51 65 80 7 53 29 37 67 32 139 69 49 33 66 147 18 152 28 48 82 88 23 84 52 44 87 148 99 121 64 85 103 141 158 50 95 115 133 19 109 54 157 81 150 21 34 36 135 134 70 3 61 111 75 17 144 129 145 106 9 105 15 114 128 155 96 11 8 86 104 97 41 12 26 149 90 6 13 126 93 98 83 71 79 72 73 77 59 100 137 5 89 142 112 25 62 125 122 74 120 159 22 91 39 94 127 30 16 146 1 45 38 56 47 4 58 118 119 40 27 35 101 123 132 2 136 131 20 76 14 43 102 108 46 60 130 117 140 42 124 24 63 10 154 78 31 57 138 107 113 55 143 92 156 110 160 153
18 Likes