1 month was justified for this kind of game though.
If it’s too short and the game is complicated then there isn’t enough time to explore it.
1 month was justified for this kind of game though.
If it’s too short and the game is complicated then there isn’t enough time to explore it.
Many thanks for this really rich and deep game.
I really appreciated the one-month format. The lockdown allowed me in one month about what I usually have in one week. I am now pretty sure there is a choice to make: go for legend or have kids! But still, one month was very nice.
I wanted to try and build some efficient functional-oriented algorithms to deal with grid-based games. This game was a perfect playground. I ended up with merging and intersecting lists of lists (list of (x, (list of (y, data))). Mixing that with an offset function, you get really efficient computations. It helps also in flood-filling or pathfinding algorithms.
I used only heuristics to choose the next moves, and I kept no records of the opponent’s mines. I could reach mid-silver this way, but I really should work harder if I want to reach legend some day!
Same types of questions as for kovi:
Can you also describe a bit more the rollouts that were used for the MCTS ?
I do like the “nonsense score” idea you brought to your AI 
EDIT: Also, I don’t get the logic of the “proba * (1 - proba)” you have described everywhere in your PM ?
The branching factor can be reduced by pruning some actions. I pruned some without regret : torpedo/trigger that have no expected damages. I also pruned some (but not many) that seemed bad : silence when only one direction is allowed (only in monte carlo and after first turn), torpedo/trigger that have too low expectattions.
Hence the branching factor remained high, and my searches were not expected to find the global optimum. But when guided, one can be confident in finding good solutions.
In the case of mcts, I expanded a node after each action (not only after turn). Also I used two distinct (decoupled) trees (one for me, one for the opponent). A typical reached depth (for expanded nodes) was of 2 turns, but with some “knowledge” at depth 3-4. The rollouts are similar to MC but with mean update (not max).
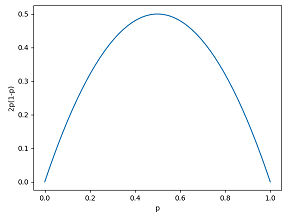
The motivation for p(1-p) to reward the detection comes from the proportion of pruned opponent paths.
To illustrate this, consider a SONAR action and let p_i be the probability the opponent is in sector s_i. Assuming there is no other action in the turn that impact detection, if you choose to SONAR in s_i :
- you will success with proba p_i and will prune 1-p_i
- you will not succes with proba (1-p_i) and will prune p_i
In consequence you will expect to prune p_i (1-p_i) + (1-p_i) p_i = 2 p_i (1-p_i).
The same holds for trigger/torpedo where sector s_i is replaced with damage area.
Notice that it vanishes for p=0 and p=1 (nonsense actions  ) and it is maximal for p=0.5 when you can split the set in two subsets of equal sizes.
) and it is maximal for p=0.5 when you can split the set in two subsets of equal sizes.
Hello again everyone,
I have performed some improvements in my code in order to beat this terrible legend IA!
It was hard, I have added these functionalities to be able to do it:
Now I am ranking 16 and truly happy. to be there =)
Thanks a lot to post the game that quickly in multi, it might seems weird but I didn’t had the time to finish all what I wanted to do during the month of the contest ahah.
P.S: I think my filling area (to compute remaining tiles) is not performant (basic BFS). If someone have a good idea to perform it (with connection points or something similar) it would be perfect =)
How can i detect if an island is around my sub?