Apart from what @Magus said, it’s also worth mentioning that current ranking system never stabilizes. Here, we could have many more games but no matter how many we had, rating would always depend only on the last few. This contest has much higher variance in general than CSB. We had partial information (only 8 following blocks), and each game was usually based on a single decision, where in most cases it was next to impossible in order to predict if it’s good or bad.
I noticed this stabilization issue as well ; I was ranked 12th when I got an incredibly bad luck sequence against players under me (27 loss, 5 wins between 81 & 112 on last matchs) which led me to rank 39 before I could slowly come back to 25th.
Hi everyone,
Thank you for sharing your thoughts about the current ranking system.
We know it is far from being optimal, therefore a team is working here to take your remarks into account and improve for the next contest.
However, we won’t be able to change the calculation for the Smash the Code contest: we’re a bit short on time to do this now.
Don’t hesitate to share your views on what we could do next, as already done in this meaningful thread, because it helps a lot.
Thanks guys for your comprehension.
1 Like
To me, the ideal ranking system for such a contest should be based on “Maximum Likelihood Estimation” theory.
(see : https://en.wikipedia.org/wiki/Maximum_likelihood or
https://fr.wikipedia.org/wiki/Maximum_de_vraisemblance )
The implications of switching to such a system are the following :
- Contrary to the current system, the matches HAVE TO be sampled randomly from the whole player pool. This means that the best player has as many chances to play against the second best as against the last.
- Maximum Likelihood Estimation can only be performed when all the ranking matches have been done. It can not be updated “live”. I suggest TruSkill is kept as a “temporary ranking mechanism” during the contest, and Maximum Likelihood Estimation is used at the end of the contest as the official ranking system.
- Maximum Likelihood Estimation is basically a method in which you have to find a set of N * (mu, sigma) values that maximizes the likelihood of observing the victories observed for each player. In essence, you will end up with an optimization problem where you find the maximum of a function with 2*N parameters when you have N players to rank. This equation will require a strong numerical solver. I know Matlab/Scilab have a well suited “fsolve()” function.
2 Likes
I feel positive about random sampling. I have noticed some kind a rock-paper-scissors effect (howewer I’m not sure if it’s not purely psychological). My bot had a hard time pushing through ranks 70-100, but could float for a very long time at ranks 60-70. My thought is that there’s a limited amount of popular strategies, and there’s only a few strategies present in the top 100. If there’s an equal number of “rock” and “paper”, and a few “scissors”, the “scissors” should be somewhere in the middle, but in current ranking system it’s pure luck if you manage to stay above “rocks” by feeding off “paper” or sink below them.
I too would like broader match selection. And Maximal Likelihood could be interesting for the “middle class” players. But in bigger picture, I see some problems here (jump straight to the conclusion below if tl;dr).
-
Having two quite different systems (temporary and official) would make the temporary ranking of much less interest (the approximation could be really misleading and result in frustration). So less submissions during the contests and less fun.
So it’s better to have one system only (should it be Max-Likely, we could run it every hour or so). -
I think the heart of the problem isn’t that much in the system of assigning points but in choosing the matches. In recent contests we had 2 or 3 similarly strong players on top, winning against everyone else and having win ratio pretty close to 0.5 between them. I do not think a uniform broad sampling would help here – actually the result would be even more random. You have to play much more matches between the best players to make a split.
Conclusion
All this makes me think that in short term FredericBautista’s idea of increasingly more matches towards the top of the ranking could be the best fix. I would only add that there might be some anti-slide protection (as for the leagues): once you qualify for, say, “top 32” and play more matches, you will never go lower than rank 32 due to loosing versus stronger players.
In long term, I think we could really develop our customized system and have more fine-grained control (not that difficult; Moser says implementing TrueSkill was a few month’s journey to understand, here is the result.
I believe an important point to find out is: Does CG have access to the Tau parameter described in the chapter 14 of the paper on the TrueSkill algorithm that I linked before and that you can find here at the end.
Here is an edited copy of the text without the formulas that I can’t copy here:
Tau (τ): The Additive Dynamics Factor
Without τ, the TrueSkill algorithm would always cause the player’s standard deviation term to shrink and therefore become more certain about a player.
Before skill updates are calculated, we add in τ squared to the player’s skill variance.
This ensures that the game retains “dynamics.”
That is, the τ parameter determines how easy it will be for a player to move up and down a leaderboard. A larger τ will tend to cause more volatility of player positions.
The default values for a game leads to reasonable dynamics, but you might need to adjust as needed.
If CG use the default setting for the Tau parameter, it means that the ranking is meant to never completely stabilize because of this Tau parameter. If they can change this setting which I believe should be possible as it’s pointed by the paper as a setting with a default value, then playing the final row of games with a 0 in the Tau parameter could be just what we are looking for.
Edit:
After checking the documentation the Tau parameter seem to be a standard setting of the TrueSkill class and it should be pretty easy to customize. I can’t say if it is the best solution but it looks like a cheap one to try.
class trueskill.TrueSkill(mu=25.0, sigma=8, beta=4, tau=0.08, draw_probability=0.1, backend=None)
Implements a TrueSkill environment. An environment could have customized constants. Every games have not same design and may need to customize TrueSkill constants.
See: TrueSkill — trueskill 0.4.5 documentation it’s the second class on this page.
1 Like
A few links and quotations for MLE (maximum likelihood estimation) :
“The basic idea behind MLE is to obtain the most likely values of the parameters, for a given distribution, that will best describe the data.”
An article which describes a very similar approach, and gives equations around it :
http://homepages.cae.wisc.edu/~dwilson/rsfc/rate/papers/paper.pdf
Various articles :
http://web.engr.illinois.edu/~swoh/slide_ismp2012.pdf
First of all, thanks a lot for your messages, as a former CodinGamer (yes, I don’t compete anymore since I’m part of the team) I understand your frustrations and I think it’s very important that the ranking reflects the skills of the participants.
Regarding Smash The Code we faced a difficult situation: we’ve used the same algorithm as before and we’ve added the same amount of battles as the last contest. We are aware that our current system has some drawbacks but we couldn’t easy say: “hmm, I think that XXX should have won, let’s add more battles to let him win”. The conclusion was simply: let’s see what we could do to improve the system, but for this contest it’s unfortunately too late :/.
I’ll will try to participate to this discussion and hopefully we’ll be able to find a solution not too long to implement (i.e. not changing the whole ranking system by another one, all the developers are already really busy). If you need details about how things work I’ll do my best to bring you the information you need.
For each game we can decide whether we need to do permutations to be fair and that double the number of games. But I need to dig into the source code to see if the league system has broken something regarding an increase of the number of games for the top players. That might explain a lot of things…
Yes we can change that parameter and currently we are using the default values. If I understand, your suggestion is to change the Tau parameter when we add more games after the submissions are closed?
This doesn’t look to hard to implement, I’d like to hear the point of view of other people on that.
Another suggestion received by email was to use as score the average of all the computed trueskill scores. This would naturally reduces the impact of the new games. What do you think?
It’s indeed what I am suggesting, I might be wrong but reading the paper, it sound very much like reducing the tau parameter would tend toward a stabilization of the player skill overall evaluation.
There might be better way of ranking players like pb4806 suggested, however the good point with this option if it works is that you won’t need to develop and entirely new system and it could save you quite some work…
The idea is that the more game are played the closer you get to the evaluation of the player skill, and at some point people only move up and down in a range that is likely defined by the tau parameter itself.
I suspect that if you never reduce the tau parameter people with skill within a range below the tau parameter generated dynamic will never ever stabilize and will keep on exchanging place forever.
Evaluating when this exactly happen might be complicated but you can maybe give it a try with empirical tweaking like say half of the games played after AI are definitive (the extra match for the legend league actually) are played with default tau and then the rest with tau=0. Or maybe progressively decreasing it.
For testing purpose you could eventually feed the algorithm with generated data and check the results.
Generating data by simulating games between predetermined skills opponents with results drawn as random with a bias based on the skills, sample size need to be large enough and validated by checking deviation.
I reckon it’s more of a trial and error attempt to find a working solution but it could work still.
On a fun note: maybe you could make an automated test frame work and plug in a GA with the TrueSkills parameters as genes and the correctness of the generated tested rankings as fitness function ![]()
Edit:
You should definitely have a look at this: GitHub - Manwe56/trueskill-ai-contest-test-tool: This tool will allow you to configure the strength of IA virtual players, and see how trueskill might rank them
This tools does very much what you need I guess. In the readme the author state exactly the problem you are trying to solve. Here is a part of the readme inside the project:
For sure, the best players are far away from the noobies, but if you take two players with a skill difference very low, you will notice that the rankings will change between them continuously. Their rank will only depend on the final cut that will be done.
After analysing the trueskill mechanism, I noted that the past matchs will tend to get less and less weight in the final score of the AI. As AI skills don’t change, I found it sad that the number of matchs wouldn’t give more precisions on the skill of the AI.
To enhance this behavior, the best results I have so far is to use the following steps:
- Run matchs with trueskill until all the sigma (trueskill confidence in its score) of each player are under a fixed limit.
- Then consider the trueskill score of a player is the mean of all the trueskill scores where the sigma is under the previous fixed limit.
- When the rankings did not change during several match played, consider we get the correct leaderboard and stop to run matches.
On top of the hints there is also source code for a ranking simulation with players using TrueSkill.
1 Like
FredericBautista : I have not taken the time yet to study all the papers you provide on TrueSkill, but I have doubts the “Tau” parameter is really what we need.
My understanding of TrueSkill is that each time you play a game, your rank is updated accordingly. In essence, it behaves similarly to an exponential moving average where old values are gradually forgotten and recent values have more weight.** If this is indeed the principle, no parameter will reduce the unwanted behavior of “forgetting old games”.**
I believe the use of “tau” is the following. Think of a situation where you have a perfect ordering of players where player A always wins against player B and player C, and player B always wins against player C. There is no uncertainty regarding the relative ranks of the player, the “sigma” value should tend towards zero. In that situation, the “Tau” parameter guarantees that sigma will never do so. Hence, “Tau” has an effect when the data already provides an “easy” perfect ranking between players. On CG, this is not the case and I do not believe “Tau” is the solution.
I really like the last suggestion you made based on Manwe’s github.I would be satisfied with a solution where Trueskill is used in two steps : score estimation, then launch new matches and take the average true skill scores obtained during this series of new matches.
I can’t seem to find it anymore, but I recall Manwe posting this suggestion of the forum some time ago ?
1 Like
I am not entirely sure about the tau parameter either as i said.
The main point is that it was a very easy implementation to achieve and to eventually quickly test on existing data. Regarding what tau exactly does the chapter 14 in the paper still is pretty much what I copied here.
You could be right though, again my point was more about trying simple stuff first. I already had doubt with it anyway but that is typically the kind of “easy patch” I would have tried before anything else.
After finding that tool by Manwe I guessed that he probably tried simple stuff like that before attempting more complex solutions and I was about to remove my tau based suggestion. I still left it here just in case…
1 Like
Here it goes, and the replay from FredTreg is worth reading too.
Actually, Manwe did some interesting work on trueSkill!
Just to let you know I’m digging through all this stuff to see how we could reliably reduce the volatility of the TrueSkill (at the moment i’m not entirely sold on this “tau” parameter, but save you the details for a more clear conclusion).
I have implemented locally the “Maximum Likelihood Estimation” method, and applied it to two model cases.
**Case #1:**This case was given by Manwe in his posts.
[quote]Si on a deux joueurs avec des niveaux j1 et j2, J’ai choisi (et c’est très certainement perfectible) que:
la probabilité que j1 gagne seras:j1/(j1+j2)
la probabilité que j2 gagne seras:j2/(j1+j2)
Si on prends des exemples numériques avec j1=5 et j2=9, ça donne:
j1 gagne dans 5/14, et j2 gagne dans 9/14
Si on a j1=1, j2=9, alors j1 gagne 1 fois sur 10 etc
En faisant jouer 1000 matchs par IA, on obtient alors les courbes suivantes pour les scores de chaque joueur:[/quote]
My results with Maximum Likelihood Estimation are the following :
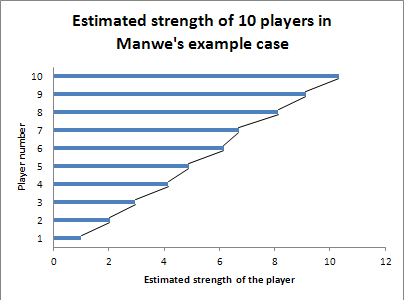
Case #2:
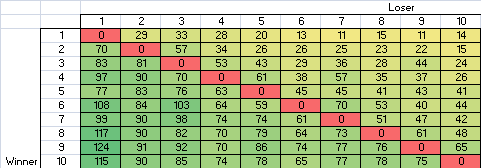
Case #2 is taken from the “Smash the code” TOP10 match history. It is a
sample of 800 matchs that I used to rank people relatively to each
other.
I don’t know how ties appear in the database, probably as a loss for one of the players…
My results with Maximum Likelihood Estimation are the following :
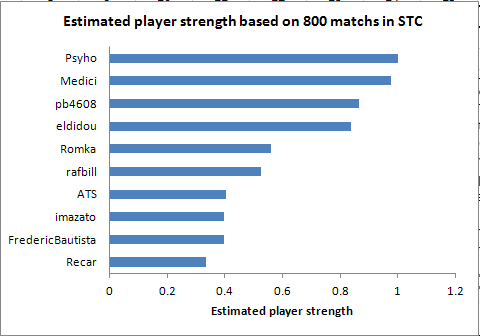
(I have to thank Magus for preparing the database)
My opinion at the moment is :
- Maximum Likelihood Estimation seems to be the theoretical best solution to fairly ranking AIs.
- Reading Manwe’s position, averaging the ranks upon stabilization doesn’t seem to be a bad solution, and might be easier to implement.
- In any case, the current opponent selection system should be modified so that the top2 players don’t play each other 50% of the time. I can provide simulations showing how much this skews the results…
- Also, the current system gives more matches the higher ranked you are. Once again, this can strongly skew the results and should be avoided in a fair ranking system. If adding new games for 2500 AIs isn’t doable, then it should be done for a subset (only 100 ? only 50 ?) but all the AIs in that subset should receive the same number of additional games.
3 Likes
If you want the data, it’s just a simple CSV : http://pastebin.com/F4uMsDk4
First column is winner, second is loser.
I extracted this from the last battles of the top 10. I removed all games against players outside of the top 10 and i carefully count every game only once (you have to avoid to count a game twice because it appears once in the last battles of one player, and one in the last battles of the other player).
2 Likes
Cool stuff!
Yeah, MLE (aka Kemeny method IIRC) seems to be indeed the theoretical best solution.
One problem is, in theory it needs something like K*n^2 samples for n players. That is, roughly all matches everyone vs everyone, maybe a couple of times. Otherwise it might be somewhat random and volatile. So while top 10 is doable, it wouldn’t scale nicely to ~2.5K participants, would it?
Choosing the top 10 (or 50) by trueSkill and then applying MLE could be full of surprises (and generating frustration). It’s better to have one global system. Fortunately, a solution might be in the links you provided in your post.[1] [[2]] (https://papers.nips.cc/paper/4701-iterative-ranking-from-pair-wise-comparisons.pdf)  (Here is a more recent version [3].)
(Here is a more recent version [3].)
It’s called Rank Centrality. Quite simple, agrees with MLE (when a model is known), needs roughly n*log(n) samples and has a performance guarantee. Looks not too difficult to implement (compute the first eigenvalue of a matrix, seems like one command in MATLAB or Python/NumPy).
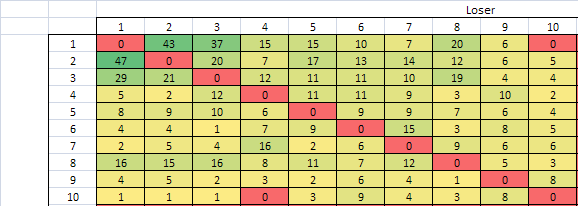
I’ve run an exhaustive check on the @Magus’ data (thanks again!).
I mean, consider all possible rankings and chose one that has the best agreement with the data.
And to compute the “agreement”, you take all pairs of players (A,B) and add the matches where A won against B. No probability here, just brute-force and clearly the best possible solution.
This is actually a well established method of constructing a ranking from individual comparisons known as Kemeny-Young rule (see also here).
Here is a simple Python3 implementation (you need to put the Magus’ data in the file STC_data.csv in the same directory).
Actually, there are two equally fitting rankings for these data, both supported by 489 matches:
-
Psyho, pb4608, eldidou, Medici, Rafbill, Romka, imazato, FredericBautista, ATS, Recar
-
Medici, Psyho, pb4608, eldidou, Rafbill, Romka, imazato, FredericBautista, ATS, Recar.
In this sense, any other ranking is strictly worse. For example, the final TrueScore ranking is supported only by 471 matches and the one provided by @pb4608 has the score of 473.
So far so good. But the complexity of this check is exponential (and ridiculous n!n^2 in my implementation). 20 players would be impossible to rank even with Magus-optimized-C++ 
Besides, to be really objective, this exhaustive check also needs a full nn matrix with every entry filled with at least a couple of matches. Good for 10 players, but impractical for 100 players.
So what I think is this.
-
TrueSkill was designed to propose interesting matches end ever-evolving rankings, not definitive one. Just think about it: interesting match means closely skilled players. “Ever-evolving” implies volatility. This is good for humans playing on Xbox and plainly bad for AI bots in time-limited contest.
-
Given the data, TrueSkill ranking wasn’t that bad. But we agree that we would like more data in the matrix of matches (there are almost empty areas). The problem is a solution based on a full n*n matrix is impractical for 2.5K participants.
-
Best known (to me) practical solution is Rank Centrality. It has many advantages:
-
It gives a stable final ranking using an optimal amount of Cnlog(n) random samples.
-
It’s frustration free in the sense that it samples randomly and agrees with win/lose tables that were brought to forum in two recent contests. Compared to this, TrueSkill is more obscure in its workings; this lack of transparence certainly adds to the frustration.
-
It’s relatively easy to imagine in terms of random walk on graph of players with edges weighted by win/lose ratios. The strong players are the vertices where the processus spends more time.
-
It’s model independent. To use a Maximal Likelihood Estimator, one has to arbitrarily choose a model (make an a priori hypothesis as to the real distribution the data is issued from). If your model is wrong, the results can be anything. RankCentrality is proved to work anyway.
-
While RankCentrality itself seems not too difficult to implement, I understand it’d be relatively costly to replace TrueSkill by another system. So I’d rather vote for averaging of results in TrueSkill. Stabilisation is everything.
-
Maybe for the top 10 we could launch the ultimate batch of uniformly distributed 2-3K matches and find the best ranking just by brute force. Yes, I do realise it contradicts my “one-system” proposition, but this might be viewed as the elite “super-finals”. The advantage is the results in top 10 are then clearly the best possible.
1 Like
There’s another aspect that should be considered: we have games with more than 2 players. The system should be able to handle that too.
Also, we have games that we call unfair: even if we do the permutations the initial position can give a great advantage. => For some games a tie (when summing all the games generated by the permutations) means that the players have a similar strength, and sometimes it just means that the initial position gives a strong advantage to a player.
1 Like
Right, obviously.
Kemeny rule takes it “natively” into account (can handle any lists of preferences).
Not sure about RankCentrality.
As for the TrueSkill, it certainly handles it somehow. But I can’t remember seeing it explained in the docs (maybe it’s just a series of pairwise comparisons? then any pairwise system could handle it). Will be digging into
Such a tie outcome contains zero ranking information in any case. So a “good” system should be calcelling the inverse outcomes from two permuted initial positions.
Kemeny rule does it “natively” (one game is +1, the other -1 to any ranking).
Rank Centrality cancels it too (it’s win/loose ratio that counts).
Not sure, but TrueSkill might be unfair here (e.g. the second game could count more than the first one by general principles of TrueSkill; not sure however how it really works).
When we use permutations,we sum the rank of all the participants after each match and at the end we consider it as a single result. And that’s where we check for a tie.