I’m using a double for loop.I had a problem with overtime.
Hello good people 
I am surprised what techniques people are using for this puzzle
I made with one simple loop. Makes me doubt in my code
Anyways, I pass all the tests, no problems but in final score i got 91% because of last test 
Anyone willing to take a look and give some clues?
1 Like
Hi @TwoSteps,
I’ve the same issue, i fail the test & validator 5 !! I really don’t see why !!
Thanks for a little help
Philippe
Test 5 is called “Large dataset (n = 99999)”
It seems your algorithm is not efficient enough.
1 Like
Anyone has problems on test case 6? I got the correct output of -3, and it shows it passes the test case. However, when I submit, I do not get the 100% score, allthough I pass all the test cases.
What I do is:
- Determine all the losses iteratively, and then extract the biggest loss from those losses.
– I determine one loss by finding the highest and lowest value.
– I substract those two, determining the loss
– For the remainder of the stockvalues, thus after the time of the lowest value. I determine if there are any other losses. Which is the case in testcase 6. - I compare all the losses and take the biggest loss
Are you sure you’re not timing out?
I am sure. It is faster then the data set with the large amount of numbers. It just returns -3.
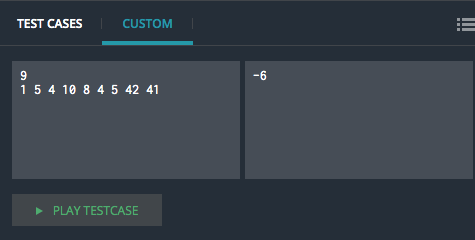
My testcase now passed, however the validator does not. What I see is that the test case is:
3 2 10 7 15 14
And the validator is:
1 5 4 10 8 4 5 42 41
I suggest you use the “expert mode” (settings on the left > mode > expert) to test a custom test in the IDE (since the validator is explicit).
1 Like
Thank you! I did not know about the custom testing. There was a flaw in my logic, where I did not take into account that the first value will be the lowest. Thanks to the custom testing, I found out.
I am playing around with Haskell (which I don’t know too much, to say the least) and try to solve this simple puzzle with functional programming.
I tried out several solutions working for small datasets but all timeouts at “Large dataset (n = 99999)” IDE test despite my code seems to be O(n).
Is Haskell this slow, or do I make accidentally something ‘too expensive’?
(Earlier I solved this puzzle in almost all available imperative languages and never experienced timeouts)
In each solutions I read the complete dataset in a list.
Solution #1 is a simple recursive function with pattern match using " | expression = value " lines. As much as I can tell, it is correct tail recursion. Number of iterations is ‘n’.
Solution #2 is using foldl with an anonymous function. Here I needed to fold not to a single Int but to a tuple (Int, Int), because I needed to carry 2 values.
Haskell pros, please help! Thx.
This is a classic.
You might want to check Foldr Foldl Foldl' - HaskellWiki
Note that since that page was written, GHC has evolved to be mostly able to optimize away the space leaks for simple foldls. But AFAIK, it’s still far from automatic for tuples, so the advice there still applies, duplicated for both components of the pair.
1 Like
This SO post might also be relevant.
1 Like
Thanks for the help, these links are very insightful.
I tried out several versions as the articles suggested: using foldl’ instead of foldl, using foldl’ with `seq, and also using Pair type instead of simple tuple. Unfortunately, still having timeout at the ‘n = 100k’ test case. I don’t have out of memory, but I have out of time (of course it still can come from the consequence of an excessive and unnecessary recursive data buildup in the stack).
Thanks anyway, playing around with a purely functional language is really an eye-opening experience (even if it involves tears  )
)
PS: Maybe next time I turn to another purely functional language: C…
(as this not so serious but clever blog article is reasoning: http://conal.net/blog/posts/the-c-language-is-purely-functional )
My program was failing in large dataset…
After deleting all System.err.println i passed this test
A good challenge could be to solve this puzzle without loading in memory the input. You doesn’t need to do it to solve the puzzle and your code will be more functional. 
1 Like
Like a lot of people here, I got a working solution (in C#) but could not pass the 99999 ints test (timeouts). If you have got to the same position, I’d guess you are also using a nested loop?
If so, you’re probably getting your inner loop to keep checking against the value in the outer loop. This works fine for small cases, but you actually end up processing the same stuff over and over.
There are quite complicated solutions suggested here involving pre-calculating differences and better processing of input etc, but my revelation was simply to remove the outer loop and keep track of the highest value so far. Any low value you find must be furthest away from that highest value, regardless of any change of direction inbetween. I’m even starting to wonder if all the logic I’ve left in for detecting direction changes is strictly necessary.
1 Like
I’m not sure about what you designate as a direction change. But with only one loop you are in the right direction
While reading data, you need to keep track of many data, update them while you are reading them for getting your decrease.
1 Like
In my last case i have wired error,
input is that
0 - 3 values
1 - 2 values
2 - 10 values
3 - 7 values
4 - 15 values
5 - 14 values
6 - 14 values
And even when I am looking on it I see that input 1 “2” is the smallest, and previouse the highest is numner 0 “3”. Simple calculation shows that answare should be -1 and not -3.???
Is logical to do with numbers 10 and 7 ?? If I do that, then I will have brake all previouse solutions. 
did You have use cerr for debugging? Hide all debuging outputs, then You should have no problem. I have this same problem with big data.
Yes, you are right. The input 1 “2” is the smallest. But you don’t have to choose always the smallest input, but the one with the biggest difference to any value before it. So 3 “7” and 2 “10” is better, because the difference is bigger than 1 “2” to 0 “3”.
1 Like