#1
For such short contests, the most important thing is fighting with time and constantly improving the bot. I had a hard time keeping the tempo. I must say the term around the end of the (pre)school year is unfortunate. Although, it is not as bad as the term including Christmas, which is one of the worst options.
Thanks to the organizers, great idea for a game.
Congrats to @reCurse and @Nanaeda for the excellent competition!
Thanks to @aCat, @gaha, @surgutti, and @Zylo for our discussions and sharing ideas.
Game
The game is interesting yet difficult to play, and the rules in the referee were a piece of cake (compared to the nightmare from Fall Challenge 2023). It was possible to get the proper engine in just a few hours, and there was space for its further nontrivial optimization.
Overview
The algorithm is a variation of DUCT, mostly fully decoupled, which is called Smitsimax here. In the basic part, there are three independent trees of the players of branching 4, but this is extended around the root. The crucial parts are bizarre management of decisions in iterations based on the number of samples and optimizing a lot.
The fully decoupled DUCT is fragile and exploitable, but I supposed that the budget is too small for a more fancy algorithm. Indeed, the number of iterations strongly affects playing strength and the bot would still improve with more iterations.
Furthermore, the behavior varies depending on the time budget and requires tuning for a specific limit; this concerns mostly the things related to exploration. The fact that there were two different processors further complicated it, so I ended up with experiments with two respective budgets, to ensure that things worked good with both. The next step could be providing two separate tunings, but there was no time for that.
Efficiency matters a lot. The following are the results of the final bot with its two previous versions (99% CI). The final bot has doubled, normal, and halved the time budget, respectively.
MSz[time 200%] vs MSz(v-1) vs MSz(v-2): 57.91% ±1.0 : 48.27% ±1.0 : 43.82% ±1.1
MSz[time 100%] vs MSz(v-1) vs MSz(v-2): 54.93% ±1.0 : 49.55% ±1.0 : 45.53% ±1.1
MSz[time 50%] vs MSz(v-1) vs MSz(v-2): 49.94% ±1.0 : 52.12% ±1.0 : 47.95% ±1.1
Algorithm
Iteration
The strategy for simulations (rollouts) is to use a policy, which is a chosen minigame that the player wants to maximize. The policy is chosen by weighting minigames depending on the current and predicted scores. It is kept for the next turns until that minigame ends or becomes fully determined, which means the outcome for that player will not change anymore regardless of the actions. Choosing an action is taking a random one from the best ones for this minigame. The best actions are hardcoded by a set of very simple rules. Stunning (in hurdle and skating) does not disable the policy, but then the player temporarily chooses another minigame and makes a best move for it. This simulation part dominates efficiency; the key is to keep it simple and fast. More sophisticated methods worked better sometimes, but not in the timed setting.
When a minigame ends, the next edition is generated, with the same distribution as in the referee. However, each minigame is generated at most once in a simulation, except for skating, which is not generated. When the generated minigames end, the iteration finishes. The scores are completed with predicted scores from future minigames, depending on their expected number of remaining editions.
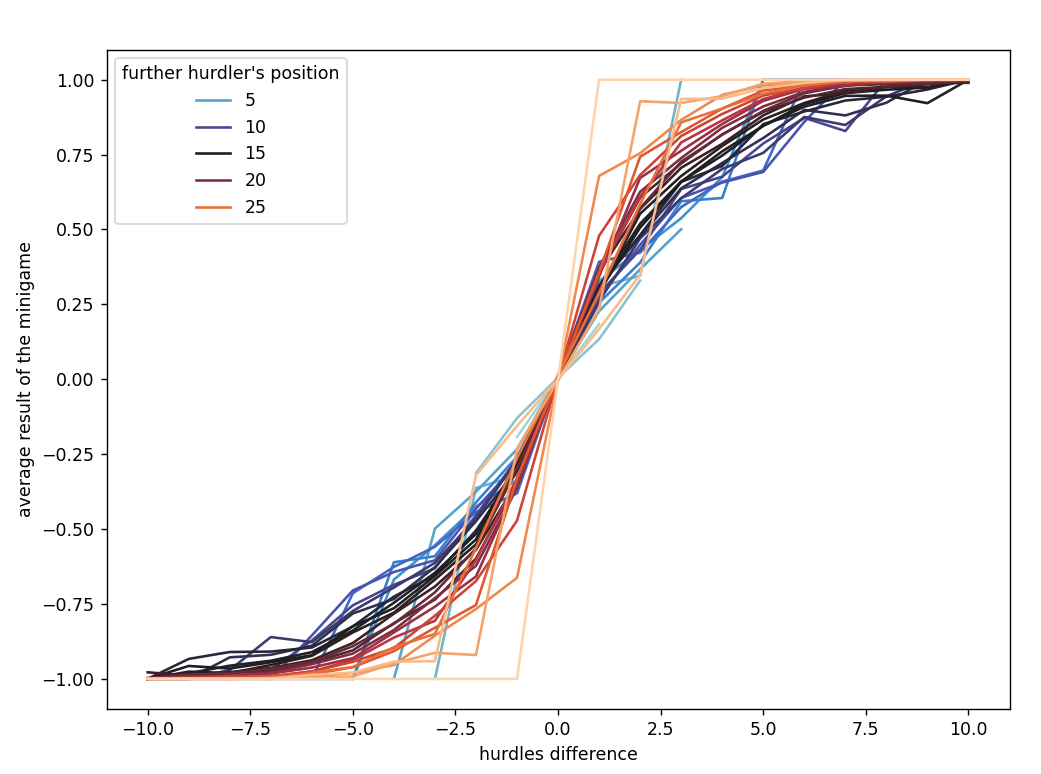
These numbers are easily calculated exactly for archery, skating, and diving, whereas for hurdle it was obtained from massive experiments with already good agents.
Playing with trees
For most nodes, the trees are fully decoupled, which means there are only 4 children for the player’s actions. However, we can branch also on the opponents’ actions, which gives 16 possibilities, and on the skating order, which gives 24. I do not want to consider branching on possible generated minigames.
The branching on opponents’ actions is taken in the root, so the branching there is 64. For skating order, a separate tree of a small depth is managed. The latter tree is used for decisions only after gathering a certain number of samples.
The important issue is to take only quality actions in simulations. First, an action is decided by UCT only if the number of samples reaches a certain threshold; otherwise, it uses the policy as above. This gives similar effects as mixing UCT with heuristic values but avoids that expensive formula. Then, there is a surprising mechanism: In contrast with the usual UCT, deciding by the tree starts from a very small exploration, thus mostly based on the choices made previously with the policy. I think this helps by keeping the statistics of the node of relatively good quality. The exploration reaches its normal formula after a certain threshold of samples, which happens only for a small fraction of the nodes at the top.
The final bot performs better when the available budget is smaller, which is mostly the result of the described threshold mechanisms employed in the latest versions. The following are the results with altered budgets but fair – the same for all agents.
[ 200% time] MSz vs MSz(v-1) vs MSz(v-2): 54.27% ±1.0 : 50.21% ±1.0 : 45.52% ±1.1
[ 100% time] MSz vs MSz(v-1) vs MSz(v-2): 54.93% ±1.0 : 49.55% ±1.0 : 45.53% ±1.1
[ 50% time] MSz vs MSz(v-1) vs MSz(v-2): 56.13% ±1.0 : 49.61% ±1.0 : 44.27% ±1.1
[ 25% time] MSz vs MSz(v-1) vs MSz(v-2): 59.52% ±1.0 : 49.28% ±1.0 : 41.21% ±1.1
[ 10% time] MSz vs MSz(v-1) vs MSz(v-2): 65.74% ±1.0 : 45.78% ±1.0 : 38.48% ±1.0
[:-) 1% time] MSz vs MSz(v-1) vs MSz(v-2): 74.45% ±0.7 : 72.17% ±0.7 : 3.38% ±0.4
The branching and thresholds are specific to the time limit. For example, increasing branching besides the root seems to be better under a larger time limit, but worse otherwise.
[200% time] MSz-IncBranching vs MSz(v-1) vs MSz(v-2): 55.04% ±1.0 : 50.93% ±1.1 : 44.03% ±1.1
[100% time] MSz-IncBranching vs MSz(v-1) vs MSz(v-2): 53.32% ±1.0 : 51.36% ±1.1 : 45.33% ±1.1
Optimization
As the number of iterations is crucial, optimization is essential. There are many tricks measured precisely to give a speed benefit.
The funniest part is precomputing all possible hurdle maps. Then generating a hurdle minigame boils down to get a random id from 1280 possibilities (some are repeated just to ensure the proper distribution). Furthermore, each map is already solved, hence getting the best actions and applying them is essentially done by one lookup and checking the stun.
The average numbers in the second turn over 10 runs on CG haswell:
Iterations: 5 264.6
Game states: 176 527.5
Tree nodes: 15 989.8 + 1 041.3
UCT calculations: 64 241.7
What did not work
Probabilities: An estimation for an unfinished minigame assuming random moves. Not that such probabilities are useless, but too costly compared to greedy decisions, and maybe not as realistic estimations, since the agents do not play randomly. Probabilities require more complex operations and/or big arrays, which are slow to access.
Weighted moves: The benefit of using a policy is not only imitating a realistic play but also in terms of efficiency – in most of the turns, we do not have to even look at the possible actions for the other minigames. Weighting moves or weighting minigames in place of random greedy decisions were too costly.
Restricting actions: Sometimes we know that certain actions are always worse than others, for example, when there is only one active nondetermined minigame. We can forbid choosing these actions in UCT, which normally tries them too. This helps, yet there are two obstacles: it is again too costly, and perhaps disturbs the statistics of a node because the same node can be used for different game states with different excluded actions.