I finished number 2 in a Code of Ice and Fire (which puts me 2 for 2 at being 2). Thanks to @Azkellas and @Tehelka for a great game, and for everyone at CG for hosting such great contests. Congratulations to @reCurse, the worthy winner.
Game thoughts
The game was interesting. Two aspects combined to make searching a nightmare:
- The action space is huge; you have many many options for moves, spawns and towers.
- Units can’t be planned independently. The other game I’ve played with a many-unit army to control is Halite 3; but there, you could mostly plan many turns of one unit, ignoring the rest of your army. Here, that’s a non-starter; the whole moveset is very interdependent.
That meant that a pile of heuristics seemed likely to be the way to go.
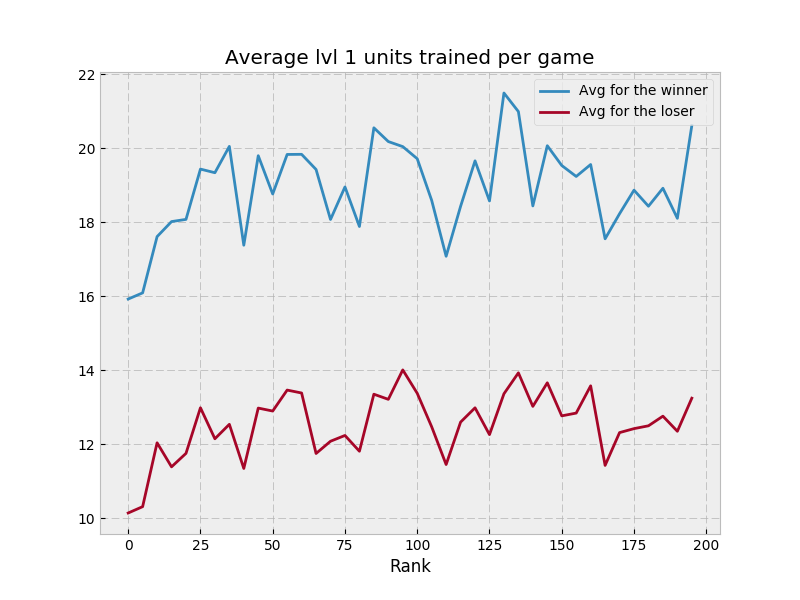
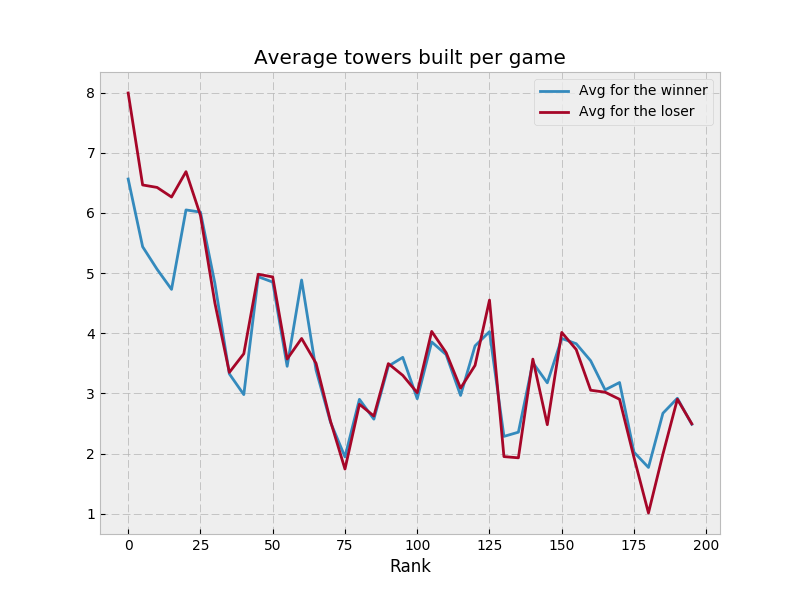
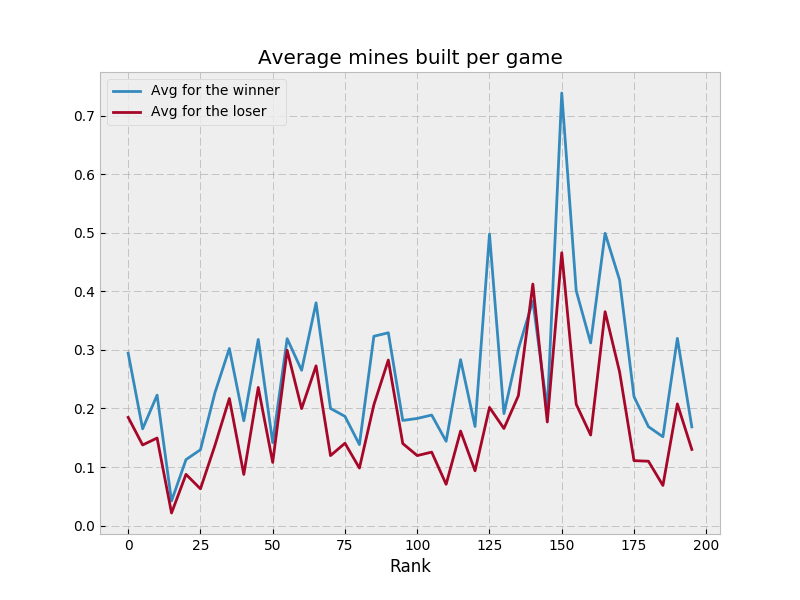
I had some concerns with the game at various points. There was a very strong early tower meta, which I worried made higher level units pretty pointless. At various times, the game seemed rather prone to large swings, but high level games mostly got over that. The one remaining problem is mines, which simply seem too weak - but overall, the game is pretty well balanced and has a lot of interesting aspects.
Algorithm
Here’s a sketch of the interesting bits of my algorithm.
Cut detection
We detect cuts for the two players in the same way; I’ll assume we are looking for our cuts against the enemy when describing the algorithm. The algorithm finds a single, best cut.
- Use a (slightly bad) variant of Dijkstra’s algorithm to calculate the minimum path from our territory to every square in the enemy’s territory, involving an initial move and then some spawns. For each square, record the parent in the minimum path, the spawn cost of the chain to get there, the total upkeep of the chain, and the level of the unit which moved at the start of it (if any).
- For every chain we find in 1, work out how much enemy territory it cuts. The score for cutting of a piece of territory is x_1 * income + x_2 * killed_unit_cost + x_3 * destroyed towers + infinity_if_HQ_killed
- Score every chain as cut_score - build_cost - x_4 * chain_upkeep - x_5 * moving_unit_level
- Pick the best chain.
This has the advantage of finding almost all good cuts, while considering relatively few cuts, which is useful because we do this many times each turn. However, it misses a fair few good ones - when there’s a good cut to a square, but also a cheaper path to it that is a bad cut.
Defending cuts
To defend an enemy cut, we do the first of these that works:
- Move a unit to a square we don’t own that blocks or reconnects it.
- Spawn a tower which blocks it. Prefer tower sites that block many possible cuts.
- Spawn a unit in a square we don’t own that blocks or reconnects it.
Flow of a turn
- Cuts. We play out lines where
i) We make no cuts, and then defend their highest value cuts until we can’t defend one (or they run out).
ii) We make one cut, and then defend their highest value cuts until we can’t defend one (or they run out).
…
iii) We make cuts until we can’t find another, and then defend their highest value cuts until we can’t defend one (or they run out).
Each of these lines of play is scored as VALUE_OF_OUR_CUTS - x*VALUE_OF_THEIR_UNDEFENDED_CUT. We play the line which scores best. This process allows us to find cuts which reduce their income or territory enough to prevent their terrifying cut. - Move our units. We process units in order of how close they are to the enemy HQ, to minimise conflicts (as units usually move that way). In order of priority, we prefer to move to square that are the enemy’s, then not ours, then not blocking this unit or an ally from empty squares, then close to the enemy HQ, then not adjacent to a friend, then close to the HQ diagonal. Except level 3 units, who only really care about eating tower and moving towards the enemy HQ. I did say this was a pile of heuristics.
i) After moving all our units, look for nasty enemy cuts. If any go through squares we’ve vacated, and we don’t have the gold to cover them, mark those moves as illegal and replan all moves. - Do another pass of enemy chains, looking for any new ones from our movement and defending them.
- Build towers, anywhere that covers a friendly square adjacent to an enemy one which is not next to another tower.
- Spawn anywhere empty with no nearby friends, or a nearby enemy square, using roughly the same prioritisation as we do for moving.
i) After spawning all our units, look for nasty enemy cuts. If cut off new units, mark those spawns as illegal and replan all spawns. - Build mines, maybe? I’m not sure I ever actually build mines, but there’s some code here that could do that.
Unfinished business
If I had more time, I would have:
- Detect cuts better. As noted above, I miss a fair few, and I think there are simple measures that would detect the lion’s share of these (for a start, detecting paths of equal cost to the minimum path to a square which link to different squares in our territory).
- Sped things up. I’m using too many Java generics, which are a bit faster for me to write but slow. I could rewrite a lot to use arrays, which would be significantly faster. That would allow me to…
- Write a better cut search. My one is currently very focused; at each stage it considers two options - make our best cut, or stop cutting and defend the opponent’s best cut. It could be both wider (consider >1 cut at a move), and deeper; I don’t model our responses to opponent cuts at all, making them hard to value. This would also involve possibly saving up for future turns (which I already do slightly for kill chains)
- Do the opening better; my units move greedily, but filling territory near-optimally shouldn’t be too hard.
- Play with some magic numbers. I never changed the values of these.
 We hope the game to open for multiplayer around next week, after we fix some “details”
We hope the game to open for multiplayer around next week, after we fix some “details”