Introduction
Rank 1! It’s been two years (already?) since I last won an official contest here, so I am obviously really happy. It was a tough competition, kudos to the other challengers for a fierce battle, you did great!
Game design
I have been on the fence on whether I like the design or not for most of the competition. The foundations are solid and gave me a good vibe at the start, but the rise and complete domination of the chaining mechanic seemed to overshadow the entire game. In the end though, I think I expected a very different game to develop and was disappointed when it turned out to be something else. After playing more with it, some more subtleties started to emerge and made me appreciate its rich depth.
Nonetheless, I still have a slight dislike of how the game state is too brittle and volatile, making it prone to a large swing of momentum that is very hard to recover from if done properly. Figuring out a move is almost like walking on eggshells, navigating a minefield of shallow traps. The meta heavily favors playing as defensively and greedily as possible to finish on one single game ending move. Not the most exciting kind of game to play or watch, but still.
Yet it is also a coding competition after all, so game design is not everything. And on the coding part, it hit very high marks. I am pleased to see the variety of ways the problem was tackled, namely on dealing with chains and choosing moves, which gave way to a lot of creativity there, if less so in actual game strategy. The branching factor was huge, which allowed both search and search-less bots to thrive, and optimization was not the absolute end-all be-all. It is also impressive to see 3 of the top 4 bots were coded in garbage collected languages!
So overall, this contest was really well done. I could comment more on design stuff I wish the game did differently, but it’s pointless. I would even recommend against making any changes when the multi comes out, as the past has shown the level of activity drops too sharply post contest. Those changes would hurt more than help, as untouched contest bots are less viable out of the box, which still form the majority of the multi leaderboard.
Simulation
The statement screamed bitmaps (or bitfields) at me on the first read. Small grid, lots of floodfill, neighborhood and surface checks… So the first thing I coded is a Bitmap class to handle all those operations, and my game state therefore contains one bitmap for each feature: walkable, mineable, active, owner (per player), units (per level), towers and mines. Combining them gave all the information needed for very fast simulation of game actions, which I did next.
The rest was pretty much run-of-the-mill implementation, and trying to minimize computing the activation map which dominated the rest.
Plan search
From now on, what I will refer to as a plan contains all the actions (move, train, etc.) consecutively taken during a single turn.
To start, actions must be generated from the current state. This list is comprised of:
- The best X chains found (more on this later)
- All valid unit moves
- Training level 1 units on all valid cells
- Building a tower on all valid cells
- Same as above, but on cells currently occupied by units, creating a number of possible move chains
- Building a mine on… just kidding. Mines are useless.
I purposefully exclude training level 2 and 3 units that are not part of a chain. I believe there is no situation under which it is a good action, because aggressive upkeep costs are crippling the most precious game resource: gold income. A decisive chain however does not make it an issue, as the game should be largely won by that point.
A simple hill climbing algorithm then picks the action from the list resulting in the best evaluation score. A new state is computed as a result of that action, new actions are generated from it and the search continues, until no action further improving the score can be found.
Chain search
I tried different approaches with various degrees of pruning techniques and results (e.g. depth-first search, breadth-first search…). Ultimately I settled on a compromise in the form of a best-first Dijkstra search performed on every valid starting position, using gold spent as the cost function. Those were either units that have not moved yet, or cells on the front line that can be directly trained on. It would then search nearby cells that were not already owned, until it ran out of money or space to explore.
It is important to note the actions making the chain were not simulated for performance reasons. And for the same reason, a different and faster evaluation function was used on every step to keep the best chain found. It was primarily based on lethality, the number of new active cells resulting from the chain, its gold cost, and an additional penalty for using level 3 units.
A further improvement that came later on was to keep the X best chains found instead of just one, to make up for the weaknesses of the light evaluation function. The real best one can then be figured out with the normal, heavier evaluation function, along with the other actions evaluated in the root search.
Opponent response
It is just as important, perhaps even more so, to anticipate the opponent moves following yours, especially if it would be a massive blunder. I originally tried to run a chain search for the opponent and executing it in the state given to the evaluation function, but it proved to be too expensive due to the massive number of calls, causing blind spots in crucial moments due to aborted searches.
What helped a lot more was to decouple computing the opponent response from the plan search, composition and evaluation step described above. So at first, a whole plan is formulated as if the opponent would not do anything, and scored as such.
Then, once a plan is completed, a chain search for the opponent is performed on the resulting state. The resulting opponent plan is added to a memory of opponent responses, and the entire plan search algorithm restarts from the beginning, with a key difference. On every evaluation, it will execute all of the stored opponent responses on the state being evaluated, score each of the resulting states and keep the lowest one, behaving similarly to a minimax search.
This process will repeat itself until it runs out of time, or until the expected opponent plan already exists the memory. In practice, this rarely exceeds 5 or 10 different responses, which keeps it fast enough. The best plan according to opponent responses is then sent to the game.
The result was a massive improvement in strength. It also allowed me later on to just run the exact same, full plan search for the opponent instead of a single chain search, once the planning got good enough.
Evaluation
This remained the weakest part of my bot for a long while, as I spent most efforts on the search described above, along with optimizing and lots of bug fixing. I was convinced I could just iron out this part later, as it was more important to have those other solid foundations first. I think it paid off tremendously, as a good evaluation on a broken search is so much worse than the other way around. It is also a lot easier to tweak towards the end of the competition, as compared to doing major algorithm work.
The main features of my evaluation function:
- Winning condition (duh)
- Number of active cells
- Gold and income
- Front line computation, defined by cells that have unowned neighbors. Mostly used to favor early aggression.
- Distance to front line, per unit.
- Minimum distance to front line, globally.
- Number of front line cells defended by a tower.
- Number of capturable cells, per unit. Mostly used to favor early spread and territory grab.
I also eventually doubled the weight on gold and income past an arbitrary turn number. This resulted in very valuable behavior changes. It stopped overspending and overdefending in the mid game, instead building up income and gold reserves to prepare attacking. This also favored very aggressive chains that would cripple the opponent income.
Miscellaneous
Having a heavily optimized simulation and bot also paid off tremendously in the form of local testing. I was able to self-play a little under 1000 games per minute, which was a great way of aggressively pruning bad changes and spotting potentially good ones.
The viewer was a bit lackluster in usability this time around. The frames were sometimes confusing in the execution and change of player turn, and matching it up with the error output was even more of a pain than usual. The lack of a debug view also doesn’t help readability, especially since level 1 and level 2 units were hard to distinguish IMO. I ended up coding my own viewer to help with those problems (e.g. big circle with 1, 2, 3 inside).
Conclusion
Thanks to @Azkellas, @Tehelka and Codingame for the amazing hard work put in making this contest a reality. Thanks to everyone for participating and making this a fun community event!
 ), and my expansion is like following a growing circle.
), and my expansion is like following a growing circle.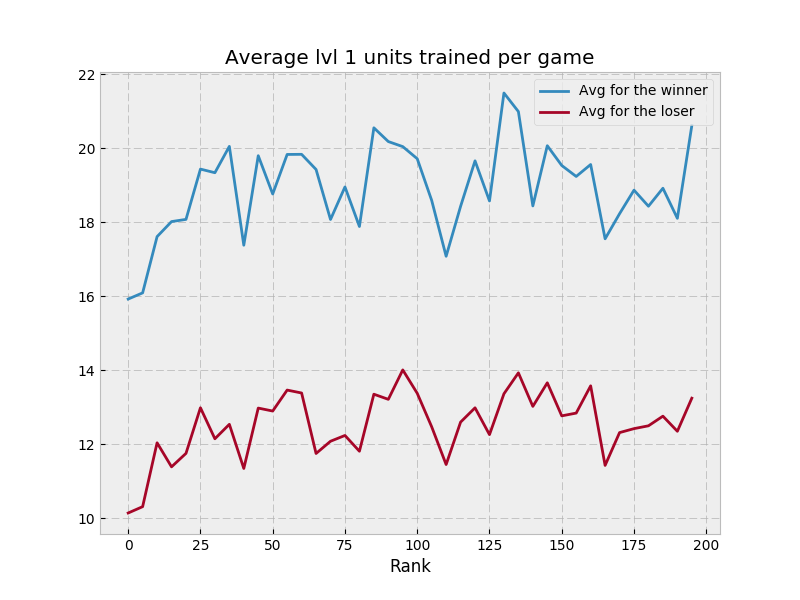


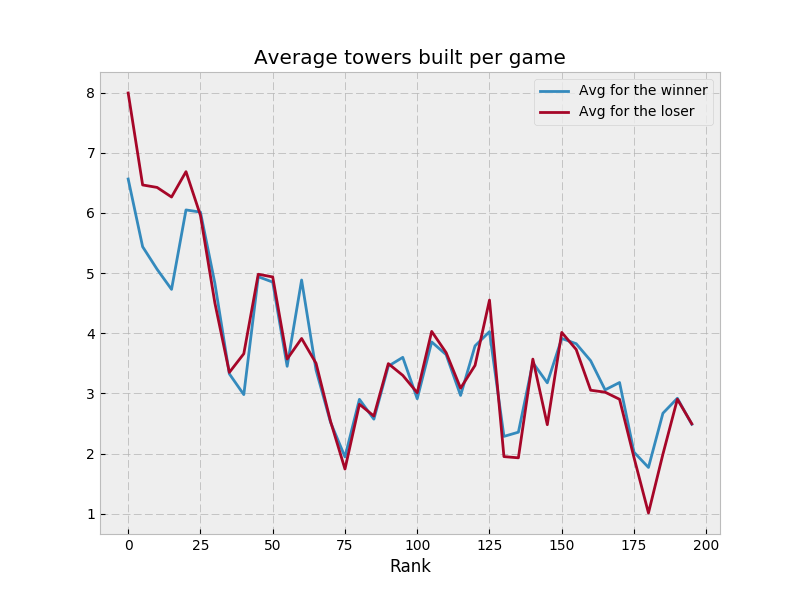
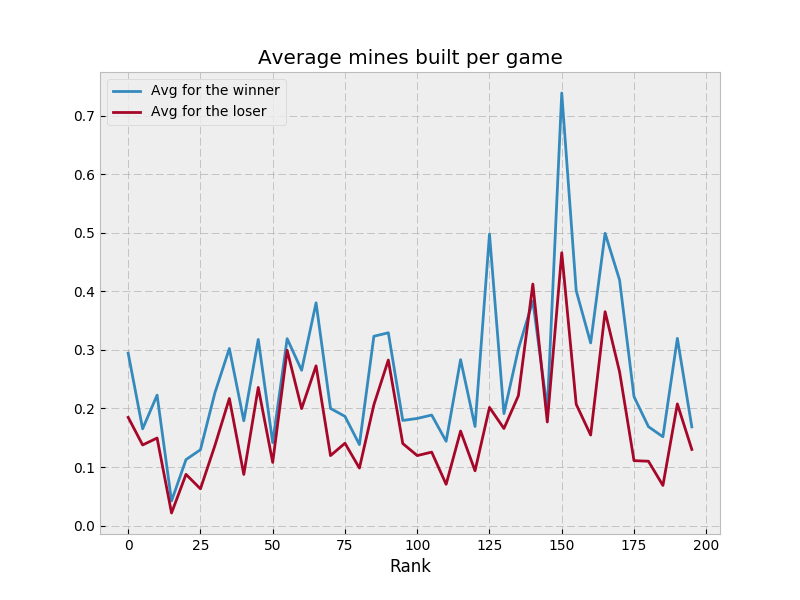
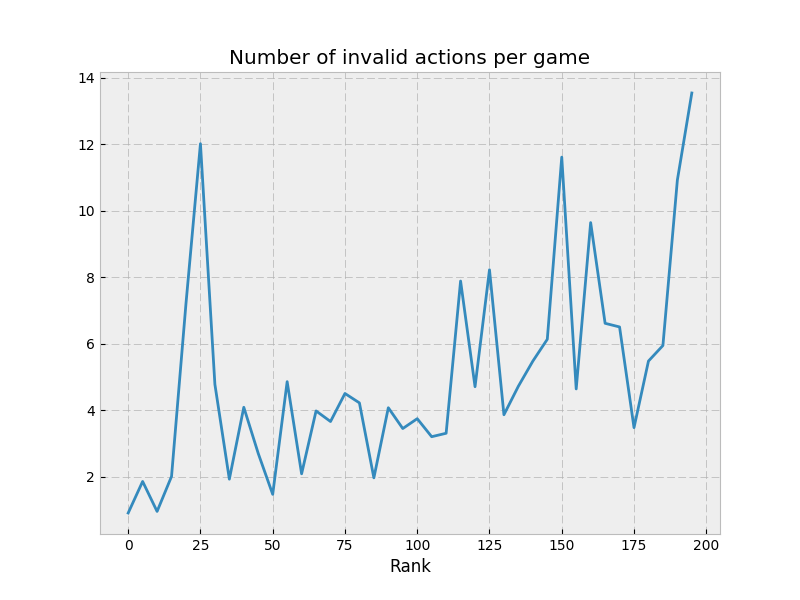

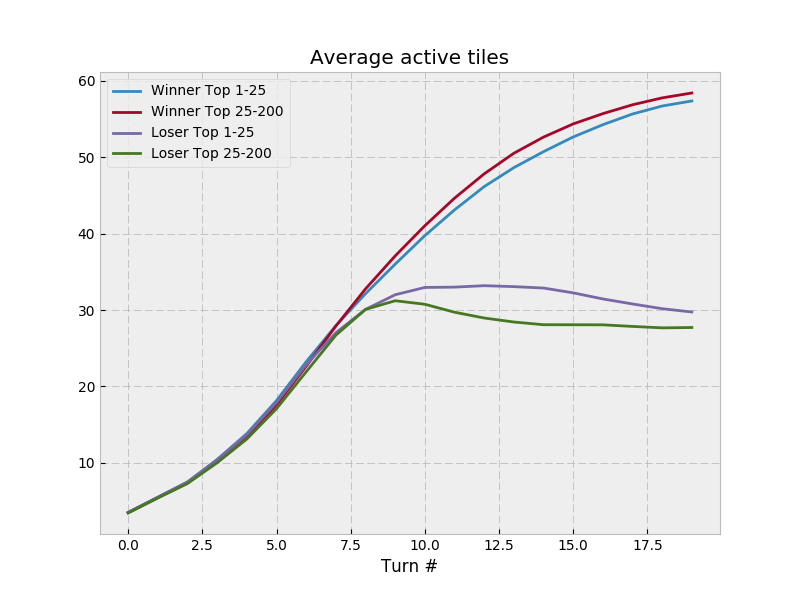
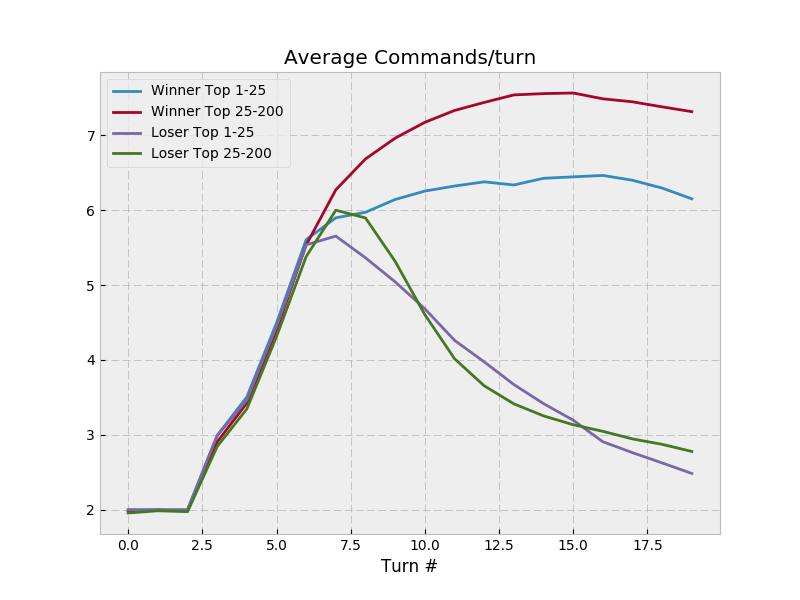
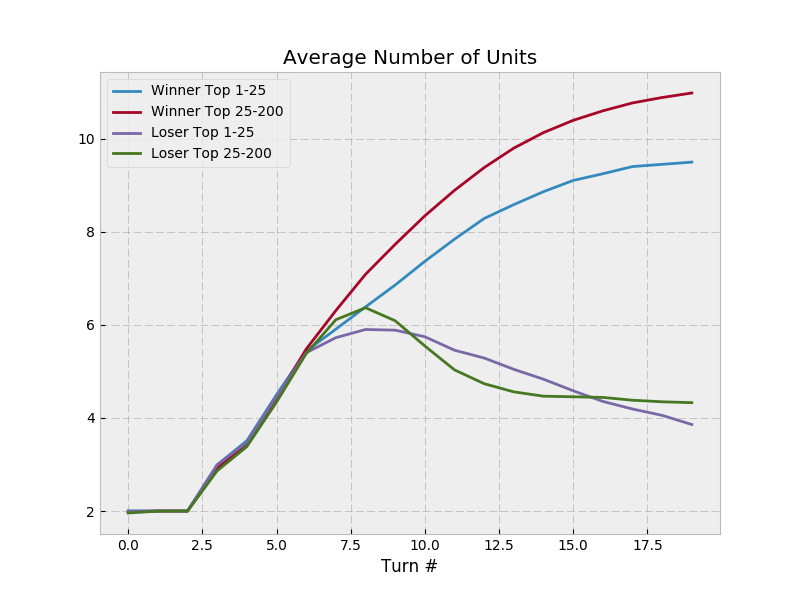

 so I’m going to copy MSmits’ format here
so I’m going to copy MSmits’ format here  I’m pretty new to Rust, and fell prey to excessive cloning, which is well described by someone else here:
I’m pretty new to Rust, and fell prey to excessive cloning, which is well described by someone else here: