Coding Games and Programming Challenges to Code Better
Send your feedback or ask for help here!
Created by @Wontonimo,validated by @Blabbage,@LazyMammal and @AdemDj12.
If you have any issues, feel free to ping them.
Coding Games and Programming Challenges to Code Better
Send your feedback or ask for help here!
Created by @Wontonimo,validated by @Blabbage,@LazyMammal and @AdemDj12.
If you have any issues, feel free to ping them.
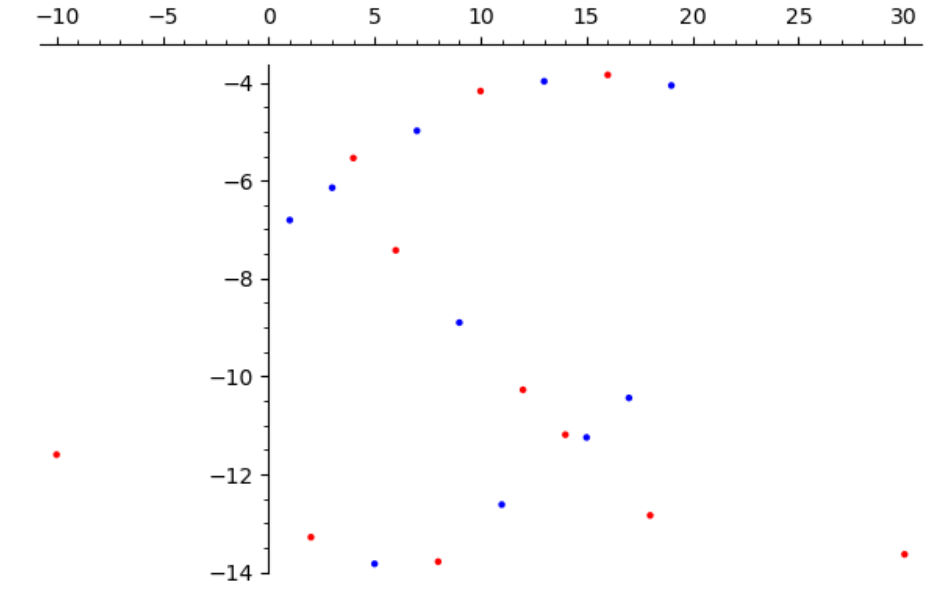
I’m surprised by the test data for the various SINE cases, which seem to be all over the place, while for the other cases they seem to make sense. For exemple the ‘Sine’ test case itself seems to look like this (test data in red) :
What am I missing here ?
Indeed, furthermore, the official solution, which is randomized, does not always pass this test.
And if we shorten the period, the sine curve can approach as near as necessary the dots.
But then SINE could be considered a valid answer to any testcase  . Following the statement, we’re supposed to derive parameters from the training set and confirm them on the test set. This implies that a reasonably good model for the training set should be reasonably valid as well for the test set, which does not seem to be the case here.
. Following the statement, we’re supposed to derive parameters from the training set and confirm them on the test set. This implies that a reasonably good model for the training set should be reasonably valid as well for the test set, which does not seem to be the case here.
Of course, as both sets are known beforehand, there are lots of ways to “cheat” in some sense…
That isnt the case Niako. A good model for training does not mean a good model for test. That is the point. The purpose of this puzzle is to find the best model that is TRAINED on the training set but FITS the test set the best. Both have to be trained using Squared Error.
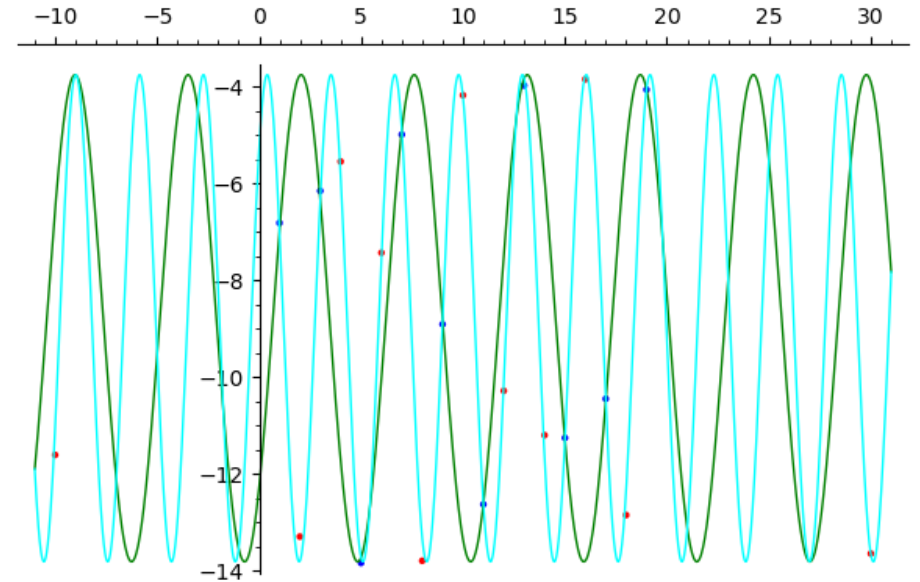
Unfortunately, I’m afraid this doesn’t work, because this is not stable at all. For instance, with high frequencies, small changes on x yield a very different y (but if you add noise only to y, then knowing how the curve was built, you may guess the actual parameters). The instability is very clear with this first test case. Depending on even a small difference for the initial guess, I find two quite different solutions :
training error 1 : 0.1182769538086592
training error 2 : 0.11827695380848437
error on test data 1 : 624.2969831075321
error on test data 2 : 1.4171311110722369
error on test data for horizontal line at -9 : 155.129754010000
And why can’t you use either fit? Why are you only constraining your solution to just 1 of the 2 sin fits?
I can, and I did. But it goes against what I understood of the goal of the problem ![]()
Use the training data to find the best a,b,c,d. Use the test data to see how well it does as a predictor.
To me, this means that you’re not supposed to use the test data to find a, b, c, d. The (a, b, c, d) of the second fit is not “better”, unless you peek at the test data.
Moreover, this all depends on the (-20, 20) limits, which also looks somewhat arbitrary. For instance, the last test case doesn’t care about a, b, c, d, there is no way to have any meaningful use of the training data. But as the test data are also apparently completely unrelated to the training data, it so happens that by far the worst model on the training data is the “best” on the test data…
Yes, the worst model in training can be the best in test. Welcome to data science as opposed to data dredging.
Sorry, but I don’t buy it : specifically designing training data and test data so that they are completely unrelated can make for an interesting “abstract” puzzle, but has nothing to do with data science (if only because there is no “data” involved to begin with).
The SINE functions have been updated to have a longer period and now have a greater separation with fitting the other solutions.
I spent a great deal of time on trying to manually implement gradient descent to find a (near) optimal set of parameters for each model based on the training data. (I derivated the mean square error functions on paper, etc.). However, I could not reach convergence for all test cases, most likely because of using a constant learning rate instead of a better approach the literature talks about, such as backtracking line search.
Almost gave up on the puzzle entirely, but I was very surprised to see that a dumb, fully random search passed all tests for me. It seems that even if the parameters found by random search are suboptimal in comparison to a proper training or search algorithm, it is good enough to distinguish between the 4 candidate models.