Coding Games and Programming Challenges to Code Better
Send your feedback or ask for help here!
Created by @DavidAugustoVilla,validated by @Eulero314,@TBali and @BerserkVl.
If you have any issues, feel free to ping them.
Coding Games and Programming Challenges to Code Better
Send your feedback or ask for help here!
Created by @DavidAugustoVilla,validated by @Eulero314,@TBali and @BerserkVl.
If you have any issues, feel free to ping them.
TLDR: in C++ unicodes are a joy to work with.
In your test cases you use the unicode \u2019 (’ == RIGHT SINGLE QUOTATION MARK) as an apostrophe instead of '. I treated it as a 2bytes character (like every other unicode char you provide) but it turns out it is a 3 bytes wide character. For all test cases and validators except validator 2, this misinterpretation poses no problem. On validator 2 however it is, as…
…skipping 1 char when we encounter ’ in “l’âme” made me skip the ‘â’ altogether, and therefore I kept both French AND Italian as valid languages for line 1 and 9 and couldn’t pass validator 2 in the first place. I passed it by considering " è " as italian-only before figuring out that ’ was actually 3 char wide and coming here to rant.
Still enjoyed the solve, cheers.
Thank you for reporting that. Yes, I’m aware there are difficulties, and it was not my intention to spring upon you unexpected surprises like that. I will modify all punctuation to 1 or 2 bytes. It would also be nice to link to some sort of guide on CodinGame which discusses the issues with Unicode, in particular to at least state which languages do not have support.
This puzzle is supposed to have the tags: Natural language, Unicode, Constraint propagation, Exact cover
This is a relatively new area for CodinGame. It was worse previously: the console had never displayed non-ASCII characters correctly (so I would have outright rejected your contribution for that reason alone if you had published it back then). I raised the issue a few months ago, and it took two or three rounds of fixes from the CodinGame staff before such characters were displayed properly.
If anybody has insights into how well different programming languages on CodinGame handle Unicode, I encourage you to start a new forum thread or a tech.io playground on the topic. Your contribution would be greatly appreciated!
I found the most difficulty in C/C++, Lua, Objective-C, Pascal, Perl, and PHP.
I had no issue solving this in PHP. You just have to remember to use the mbstrings standard library functions and not the "normal’ string functions.
There was one thing needed extra care: CG supports so ancient php version that the “split unicode string to letters” function is missing, but there is a simple documented workaround available.
My code is like this:
if (version_compare(PHP_VERSION, '7.4.0', '<')) {
$letters = preg_split('//u', $text, 0, PREG_SPLIT_NO_EMPTY) ?: [];
} else {
// @phpstan-ignore-next-line function.notFound
$letters = mb_str_split($text);
}
I am not sure whether my browser can display all diacritics correctly to allow me to copy the information correctly. Below is the image I can see from my browser.
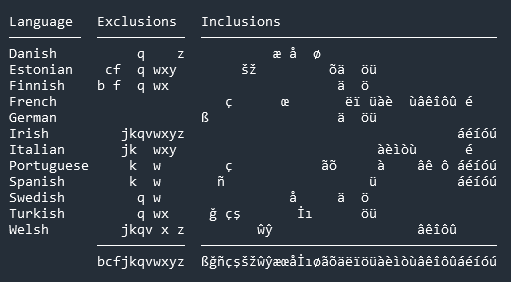
Could someone check and affirm that this display is correct? (particularly on the Irish line)
It is correct:
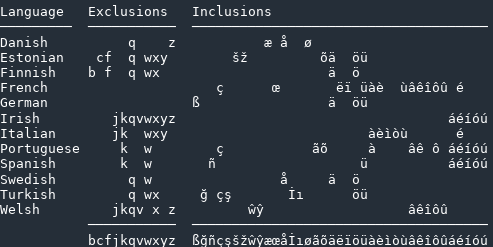
Thanks nicola.
Then there is a further problem.

In the Moby-Dick test case, the Irish string contains a latin cap letter I with acute. This letter is not included in the basic information table.
The table includes the lower case letter i with acute. Is the puzzle assuming coders should transform all lower case diacritics letters into upper case, or reverse, themselves?
It is potentially difficult because not everyone have a general knowledge in dozen of human languages.
Better to have the table be complete with all forms of possible letters at least enough to cover all test cases.
Yes, you can translate the text into lowercase. Uppercase and lowercase exist in these languages written with Latin characters.
As far as I know, in Turkish, the uppercase of ı is I and the uppercase of i is İ.
Welcome to natural language processing! Yes, languages are complicated. The uppercase of German eszett (ß) is two characters SS, and Turkish differs in treatment of i as nicola described. As far as I know the only other exception in letter case is Greek sigma (Σ), which has two lower-case versions depending on the position in the word. But as far as language goes, we’re barely scraping the surface here!
Anyway, in this puzzle you can actually ignore uppercase letters and still pass all the tests and validators. However you choose to solve the puzzle will work, if you make it work. Personally I think it’s valuable to have real world challenges, and truly earn the Natural Language and Unicode badges. Speaking of which, what happened to those tags?
Edit: I’ve updated the description to include an example in English which at least hints at there being uppercase variants.
I was surprised to look thru solutions, because the puzzle turns out to be a bit easier than intended. There’s another case that never made it into any of the tests or validators. I know I needed to cover both cases at one point during its creation, so I don’t know when exactly that changed. Thus far about 40 people have attempted, and adding additional tests would only affect 30 some solutions. You all would hate me tho.
You can post your extra test cases here to let anyone try it and get the code improved, yet does not affect submitted codes.
OK this is very weird but I may have been wrong about an additional check potentially being needed. It helps when the problems aren’t set up so nicely, but with every test case having a 1-to-1 solution, just one check appears to always lead to it, and the other is superfluous.
Python .lower() turns, for case ‘Pride and prejudice’, the first character İ into lowercase i. Is there a cleaner way of solving this, rather than explicitly excluding İ from being lowered?
Because the Turkish lowercase for İ is i and the Turkish lowercase for I is ı.
Are there any reasons for you to use the function .lower()? My solution doesn’t care about letter case at all.
The statement only gives inclusions and exclusions for lowercase letters. I automatically assumed that hence I should process everything as lowercase - but now I think of it, give that the statement does not say anything about capital letters, I should probably ignore them instead.
I assume that when you say ‘my solution doesn’t care about letter case at all’, that you simply ignore all upper case (meaning that upper case letters give as little information as punctuation)?
Out of curiosity, if you happen to know it - why is İ the included in the ‘inclusions’ in the statement, if it is a capital letter (while no other capital letters are included)?
Yes, all characters not mentioned in the statement are ignored, kind of…