Here is a topic to give your feedback & Strategies after the challenge.
Here is a write-up of my solution (5th place): Frictionless Bananas - CodinGame Summer Challenge 2025 Entry
Multi-tree MCTS for movement, heuristics for combat.
11 Likes
Hello, I finished in Legends. I quite enjoyed the game overall. The only feedback (that many gave already on Discord) is to have the old way of beating the boss in Wood leagues as the current one kind of pushes you to quick and dirty hardcode just to get to bronze instead of creating something you will be able to re-use later on.
I did not bother about performance too much in this contest given the search space, so I decided to focus on 1 turn simulation. I simply coded the referee logic in Rust and I was ready to go. Since I do 1 turn simulation I do not need any pathfinding, I just generate moves on neighbors cells and see if I can go there in my do_moves logic.
To get to a viable solution I generate a random set of actions for my agents that I mutate and evaluate each time. The core of the thinking I put in this contest is in this evaluation function. As I simulate 1 turn, I need to make sure my bot will not do something stupid just for the sake of getting a good score this round, that then ruins the rest of the game. For this I gave a bonus to holding bombs, that can only be outweighted if I inflict enough damage to enemies. To favor some control of the map I try to go towards the center at least in the beginning on the game. There is also the obvious score and wetness being accounted for. Giving bonus for a kill or getting some enemy > 50 wetness. I also tried to alter the behavior in cases where I am winning by controlling zones, to play less aggressively and favor defense.
Since we are playing simultaneously I wanted to have some predictability of what my opponents does. For this I run the logic for 10ms for my opponent considering I do nothing. I then consider the output of this as input for my agents actions. To avoid the waste of resources in this construct I had to consider throwing only on cells where the opponents is currently, because if my prediction was wrong I could end-up wasting some resource. Guaranteed damage vs possible huge bomb damage not being considered.
And that’s basically it, nothing really fancy just trying to transcript the behaviors I was seeing in the game to my eval function. I mostly tuned things using psyleague to see how the weights in my eval would work together.
What I failed in : I tried to incorporate a ratio of damage/cooldown to avoid wasting a shot and introduce some kind of multi-turn logic for shooting in my 1 turn sim.
6 Likes
I used a modified version of smitsimax to finish #2.5 in the legend league. The selection of the first action happens like you’d expect. Every agent has its own tree, and the action is chosen by an UCT-ish formula - I added a bit of randomness to it to account for the unpredictability of opponents, and also a malus for choosing to throw a bomb that’s not guaranteed to hit a target (only for my agents, not for the opponent’s agents). Moving and fighting actions are not considered separately here - one action at this depth can be e.g. “move to (5,3), throw bomb at (9,3)”.
At depth 2, things start to get weird. After an agent performs an action, it’s not guaranteed to always end up on the same square (collisions), it is not guaranteed to have the same number of bombs (collision → being out of range). The collisions are the reason why the child node of the tree isn’t chosen based on the action taken, but based on the position, the number of bombs left, and the cooldown.
That still doesn’t address another problem - if an decides to throw a bomb, this throw can be evaluated very differently based on the actions of other agents - for example, hitting a friend instead of an enemy. That’s why at depth 2, I need to choose actions differently:
- I use PUCT with a handmade predictor to be able to quickly evaluate actions that haven’t been previously visited very often
- Move and fight actions are split because I want to have more stats for each of them, and the action I choose is the one that maximizes the sum of the two PUCTs (which is not the same as picking the best move and the best fighting action, because they might not be compatible)
- There are 5 fighting actions, 4 of which have enemy agents as targets: hunker, throw bomb, 3x shoot (which of these three actions is available depends on the predicted attack multiplier from covers and range)
- If the action chosen is throwing a bomb, the actual square the bomb gets thrown at is one of those that will surely hit the enemy. Among those, I pick the one that’s closest to the other enemy agents (at the time of writing this, I came up with the idea that I should have also valued not hitting my own agents, and this would have been worth 0.07% winrate in 10000 selfplay games)
After the 2 sets of actions, I don’t simulate anything else and I go straight to evaluation. The evaluation function sums these things:
- (hp+10)*(dps + c1 + c2*bombs) + c3*bombs - c4*dps*cooldown for every agent
- a malus for being too far from the enemy
- in the first [map height - 2] turns, the distance from the squares that were equidistant from both teams in the beginning
- 2.5*(my controlled squares - enemy’s squares). No, I don’t use score in any other way. I tried a lot of things, and the bot didn’t win more games than just with this.
- I don’t consider covers; yes I tried
The “0.07% winrate in 10000 selfplay games” sums up this game about right - once a bot gets good enough, almost nothing matters, because the games get decided by rock-paper-scissors decisions when bots are throwing bombs (or just pretending to). My bot was definitely no better than zasmu’s - 0.001 score is nothing on CG, especially knowing that when legend opened, my bot had a one-on-one fight there with viewlagoon, which I won 149-148, and ended 0.8 rating points under him on the leaderboard. According to winrates against the individual opponents in the rerun, in the last hour bowwowforeach probably just found something that worked better against specifically my bot’s RPS decisions, as he started winning ~60% vs me instead of ~45% like before. I can only admire his courage submitting that change so close to the end of the contest, when everything was almost impossible to test with so much noise.
That’s to say - the game was bad (CG really likes simultaneous moves these days - here it clearly didn’t work), the ranking system was inadequate, and the number of games in the rerun insufficient.
14 Likes
Hey Frictionless! What was the depth of your MCTS? Congrats on this 5th place and winning the past contest ![]()
Congratulations.
How did you identify separate trees would work better than single tree and heavy pruning ?
the question doesn’t make sense; I don’t know whether it would work better (I get much more, but also much less reliable stats for each action), I’m not sure how do you even prune with these algorithms (per agent seems not nearly smart enough) when you can have 200000+ actions to consider per turn after fusing agents’ actions (can you even afford to loop through them all?) and you’d need to get it down to like… 50? 100?, and my reason to separate trees was simply that I couldn’t think of any simple heuristics that wouldn’t probably require a 1000-line if-forest to be at least somewhat decent and not overlook good options
Finished at #17
Used an UCT Forest, with one tree per agent. Fixed depth 3. Each tree works like a single-player MCTS, with UCT formula for selecting a child node to play. After selecting a move for each agent in the current game state, I simulate the moves happening simultaneously. The trees will converge to decent move paths, and then adapt to counteract or cooperate with each other. So the trees search together for an equilibrium. (I don’t know if this is really sound, but it works in practice)
I separated the step part of the move from the fight part of a move. Because the fight action always takes place after the moves and collisions, we can treat them as two separate moves in the search tree. It does mean that the fight move includes options that are invalidated by the step move (eg. stepping out of range for shooting), but that’s a reality anyway with UCT Forests. If an opponent agent kills your agent, it kind of invalidates all future moves as well. Separating the two keeps the branching factor a lot lower.
I don’t use traditional MCTS rollouts, but instead a handwritten eval. The reason for this was that I was originally planning to use neural networks for evaluation and move priors. I found out too late that my neural network inference functions have a nasty intermittent memory corruption bug. I didn’t have time to find the bug, so I had to drop the NN plan.
Overall a nice contest, too bad I wasted a lot of time on an idea that didn’t work in the end. I feel my eval and pruning could still be improved a lot.
9 Likes
Hello, I finished in legend (100th place), I don’t really know if what I did has a proper name.
Each turn, all agents try different moves according to my rules, adding a score depending on how their decisions affect the state. Then from all the states generated from the moves I do the same for the actions. At the end, the state with the best score is chosen.
I know it’s not optimal and I miss states that could be better, I didn’t even try to optimize anything, it can be improved a lot.
If interested, I wrote more about the how I evaluate the moves and actions here: My Codingame summer challenge 2025 solution - Evalyte
3 Likes
Hello, I finished #3 in Legend. I started with a GA against a fixed opponent solution, but this was obviously not going to be enough for this game. Better opponent prediction would be needed.
So I started optimizing alternately for myself and the opponent, keeping multiple solutions for both sides. I go depth 3 in 3v3 and depth 2 in 4v4 and 5v5. To speed up the simulation, I precompute a bunch of things: Manhattan distances, path distances, cover, adjacency, bomb hits… I also use caching for control zone calculations, since I realized I was calling this with the same agent positions a lot of the time, and indeed there are far more hits than misses. I prefer throwing 100% guaranteed-hitting bombs but also allow others in move generation.
The evaluation includes score, wetness, bombs, a penalty for being too far from opponents, a penalty for being too close to the bomb thrower (for gunners and snipers only), and a cover bonus for gunners and snipers. Gunner wetness is worth twice as much, as they are the major damage dealers while shooting.
Thanks to CodinGame for the contest. Congratulations to everybody, and especially to bowwowforeach and blasterpoard. Also, thanks to aangairbender and psyho for their amazing local testing tools.
17 Likes
#9 in Legend
I used a genetic algorithm (GA) where I had two populations (one for each player).
Evaluation of a person (moveset) was done via performance vs the opponent’s pool, using an evaluation function of the resulting game state (1 move ahead). The evaluation function had tons of factors and was very messy and difficult to improve/optimize (tons of parameters, which were optimized via selfplay performance using scripts/parameter sweeps).
After 8 generations of evolution, the two pools had a collection of reasonable strategies for both players for that turn.
I then took that set of possible strategies and used CFR+ to solve the resulting large matrix game to find the nash equilibrium. Lastly I chose the move with the highest probability (I also tried moving randomly according to the nash equilibrium but that seemed to do worse).
Thanks to everyone for a fun and challenging competition!
15 Likes
[Legend #59] [Neural network]
Neural net guy here! ![]()
Someone had to since reCurse wasn’t here haha.
RL environment
- Observations: Each bot has a vector of 114 features, including its stats, the stats of all other bots, the relative position of other bots, the map of covers in a radius of 4 around the agent, and global info such as the scores and round.
- Actions: Each bot has 190 possible actions: for each of the 5 moves, it can either hunker down, shoot one of the five enemies, or throw a bomb around him (with a filter to prevent it from bombing itself).
- Action masking: Invalid actions (like shooting a dead enemy) are masked out, but also throwing a bomb too far from an enemy (which helped a lot otherwise it would struggle to learn proper bomb placement).
- Reward: Very simple, +1 if the agent wins, -1 for a loss (and gamma=0.99).
Architecture
I started with a pretty simple MLP (i.e. only linear layers and ReLU activations), controlling each agent independently. That worked quite well, but in order to make the bots cooperate more, I added some layers to make the bots communicate when choosing the action.
Eventually I used an MLP Mixer, which is a quite fancy architecture but is more suited than a Transformer because it makes the time mixing layers much more parameter-efficient and the implementation simpler.
I made a quick sketch of both versions of the model (V1 is the MLP for each bot, and V2 is the MLP Mixer):
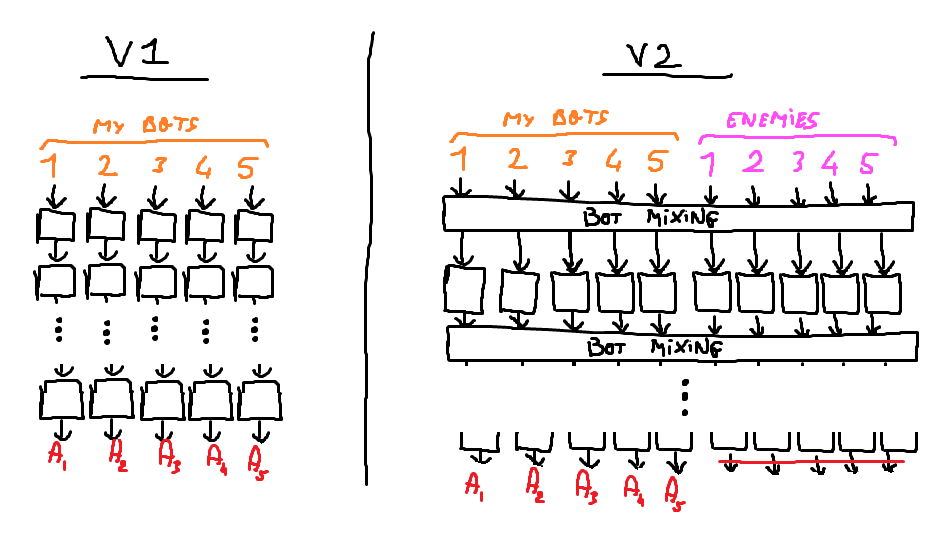
Training
I used PPO for training the agent, which played against itself. All my code was in Python so the environment was quite slow, but still with my laptop’s GPU I was able to train agents well enough.
I had some difficulty balancing exploration and exploitation, especially for bombs. I found very useful to pretrain the agent on online games before the actual RL training. That saved the bot a lot of time since it could start with a somewhat decent policy and didn’t need to discover everything on its own. That also allowed me to use larger, deeper models, which without pretraining would struggle to learn anything.
The final policy network has about 175k parameters, which I managed to fit into the 100k character limit of codingame ![]() .
.
Throughout training I was logging some game stats like average damage dealt, damage absorbed with covers, bomb damage to enemies, bomb friendly fire… This helped me ensure the agent was actually changing its strategies.
Notes, remarks and future work
- I had tried very different architectures such as a CNN, which would have a global view of the board and then pick an action for each bot. But actually, having a more agent-centric approach as I did worked better.
- Fun fact: the agent does not see the whole map!! It only sees in a radius of 4 around ally and enemy agents.
- There is a lot to optimize, like writing the environment in C++, or tuning the PPO hyperparameters, which I didn’t have the time to do.
- Maybe reward shaping would have helped with exploration, I didn’t have time to try it either.
- The agent does not always place bombs optimally, even in obvious cases. I am not sure why, so there definitely is room for improvement!
This challenge is in my opinion much harder to do with RL, as with self-play only the agent would usually converge to a Nash equilibrium that is not very interesting. Pretraining it on real games helped a lot, but I still believe that in addition to self-play, I should have added normal opponents to prevent the agent from sticking to one strategy.
Anyway, this was a very fun challenge, thanks to the codingame team!
17 Likes
Hello,
This was a thrilling and intense contest — thank you to everyone who participated.
I’m truly happy to have achieved 1st place.
My Approach
I used DUCT (Decoupled Upper Confidence Tree) for search.
Each agent’s movement and combat decisions were treated independently, effectively doubling the number of agents in the search process.
I did not perform any playouts. Instead, I relied on a handcrafted evaluation function to score game states, and used those scores directly as values.
A significant amount of effort went into designing and tuning this function.
Key Techniques That Made a Difference
Control Tile Optimization with Bitboards
The biggest performance bottleneck in simulation was the calculation of control tiles.
By using bitboards and bit shifts, I was able to greatly speed up this computation, which allowed for a much higher number of search iterations.
Bombs Only Thrown When Guaranteed to Hit (With One Exception)
I initially enforced a rule where bombs were only thrown if they were guaranteed to hit.
This change alone significantly increased my win rate.
However, about two hours before the contest ended, I began consistently losing to blasterpoard.
After investigating, I realized that their BOMBERs were throwing non-guaranteed bombs at mine, which caused my BOMBERs to get eliminated before they could use their own bombs.
To counter this, I introduced an exception: BOMBERs are allowed to throw bombs even if they aren’t guaranteed to hit, but only when targeting other BOMBERs.
If I hadn’t made this fix in time, I would have definitely lost.
Evaluation Function and Parameter Tuning
I spent a large part of the contest improving the evaluation function.
In the final version, it included around 36 parameters, which I tuned using Optuna, a hyperparameter optimization framework.
The parameters were optimized through self-play, focusing on maximizing win rate against earlier versions of the bot.
Thank you for reading. I’m looking forward to competing with you all again in the next contest.
26 Likes
Hi @zasmu and congrats on the 3rd place
I started with a GA against a fixed opponent solution
What position on the leaderboard did you reach and in which league, using this strategy?
but this was obviously not going to be enough for this game
How did you determine that it’s not a decent strategy for this game?
I’m asking, because I’ve used the same strategy but could not manage to escape the Gold league. Even though I have around 6 to 4 win ratio against the Gold Boss…
It momentarily reached first place right after the opening of the Silver League.
There are a lot of interactions with the opponent; optimizing against a single opponent’s solution would be overwhelmingly optimistic about what they will do, and you would end up getting crushed.
1 Like
Thanks. My current goal is just to reach the Legend league during a contest, I never have managed to do so. I want to see if this approach could get me there and afterwards to optimize further with more complex search. I think I was really close, but I couldn’t optimize enough my evaluation(I had only the last day of the contest to do so). At the moment I’m simply returning the score difference plus the team wetness difference, which is obviously not enough.
Did you use the same evaluation approach (that you’ve described) for your GA?
The evaluation includes score, wetness, bombs, a penalty for being too far from opponents, a penalty for being too close to the bomb thrower (for gunners and snipers only), and a cover bonus for gunners and snipers. Gunner wetness is worth twice as much, as they are the major damage dealers while shooting.
Hi bowwowforeach, congratulations on the win ! Can you elaborate about how you handled movement and combat decisions independently? Does that mean that you had one tree for movement and other for combat? If so, how many children did combat tree nodes had? Thanks.
Yes, more or less, probably a little simpler.
1 Like
4th
My solution is similar to that for Cellularena (Winter Challenge 2024). There are two parts to it and they are mostly independent, which made it convenient to experiment, as I was able to replace a single part of my solution without touching the other.
Selecting action-sets for a single game turn
This part of my solution focuses on selecting the K (between 4-24) most promising action-sets (combinations of actions for all agents under my control) for just a single game turn. I ended up using a simple, non-adversarial GA that evaluates the state after applying all the actions. The search phenotype consists of up to 5 actions (each action includes both movement + combat) and is initialized randomly. Mutation operator replaces a single action with a new one, also selected randomly. For my opponent I also run (a lower effort) GA to determine and freeze a limited number (up to 5) of their possible action-sets and I select the most pessimistic of them in “max min” fashion.
Deep search over the action-sets
This is an outer search that internally launches the inner search (described above) for every game state it encounters to limit the number of possible action-sets. As for the specific search algorithm, I am using a beam search with depth up to 8 full game turns (but it usually finishes early between depth 4-6). Beam width varies on different depths, but it lands up somewhere between 20-30.
Heuristic score function and performance
I used the same heuristic score function to evaluate states in both parts of my solution. The function ended up pretty basic - it includes territory, agents’ health, bombs and distances from the opponent’s agents. I tried adding more components to it, but it didn’t seem to help.
I invested a significant amount of time optimizing the performance of my solution. I am utilizing AVX instructions to speed-up the territory computation. In the end, during a 50ms turn, I am simulating and evaluating between 100k-170k game states (depending on the specific VM and seed).
As usually, I truly enjoyed this competition and I am looking forward to the next one. Congratulations to the winner: @bowwowforeach and the runner-ups: @blasterpoard and @zasmu.
14 Likes
Legend #15
Hi, I tried Decoupled-MCTS with a single search tree: https://www.mdpi.com/2076-3417/13/3/1936
Each agent maintains its own statistics to select its action, but the joint action is used to expand to a new child node.
This solves the issues with collisions/missed shoots/bombs since you reach the real resulting state, but reintroduces the explosion of nodes as the agents explore their options.
So I added a threshold of visits required to expand the tree as a workaround.
Thanks to CG and all the competitors for this contest!
8 Likes