Legend 1st, C++.
Above all, a big thank to Chimney42 , Iuliia , rnkey et Tzupy : that was a great challenge!
The main originality of the game was undoubtedly the importance of simultaneous actions.
Thus my priority was to find an algorithm that could meet this constraint. Decoupled MCTS seems to be ideal.
As a bonus, it also allows to take into account the random part of the game (the appearance of new quests).
I love MCTS
The Monte Carlo Tree Search (MCTS) algorithm consists of 4 steps (selection, expansion, simulation, backpropagation) as shown in this figure.
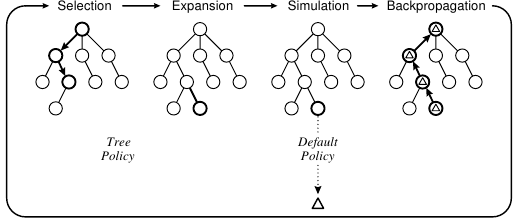
In its basic form, the simulation step evaluates the value of a position by playing random moves. It must be admitted that in this form the MCTS has not been very successful.
But in recent years a very active community has been offering variants that exploit the specificities of the problems encountered.
The most famous example is the DeepMind algorithm for the Go where an MCTS uses 2 neural networks in the simulation phase (one to evaluate the position and the other to generate “better” random moves) [ref].
MCTS is no longer rigid and becomes a very flexible canvas that leaves a lot to creativity.
It also adapts very naturally to many situations (simultaneous move games, multi-player games, puzzles…).
That’s why I use the MCTS more and more frequently on Codingame: Ultimate Tic Tac Toe (2 players), Tron (4 players), Mars Lander (optimzation)…
Note: I do not distinguish between MCTS and what could be called UCT (UCB applies to Trees).
Decoupled MCTS
Decoupled MCTS is the version for simultaneous move games [ref]. This variation modifies the structure of a node as in the following figure:
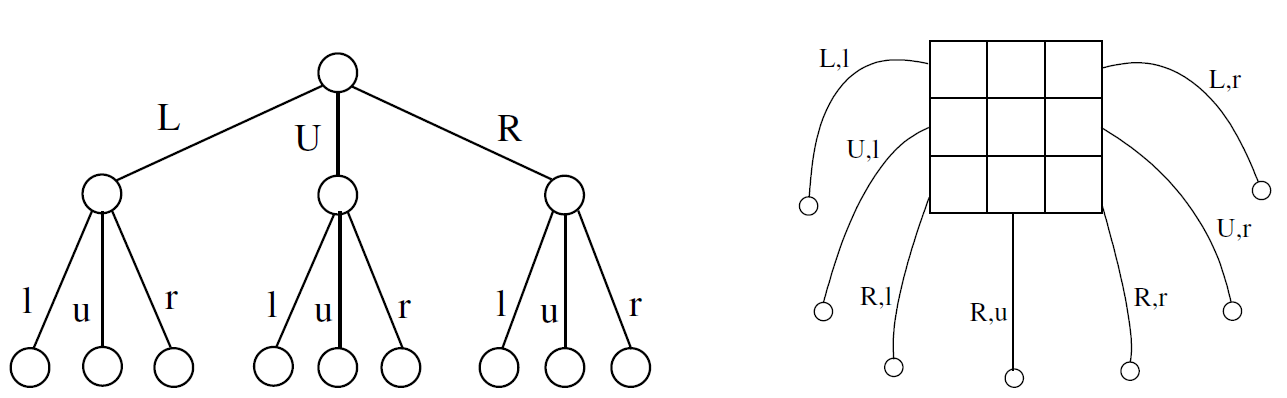
In the sequential form (left) each node represents the child node of the corresponding move (L,U,R for Player1 and l,u,r for Player2). In the decoupled form (right) each joint move leads to a child node from a combination of moves for Player 1 and Player 2 (only 7 of the 9 joint moves are shown).
In this variation the selection of a node is done through the simultaneous selection of an action for Player1 and an action for Player2. The term “decoupled” reflects the fact that (in a given node) the choice of the Player2 does not depend on the choice of the Player1.
Let n1 and n2 be the number of actions of Player1 and Player2. Then there is n1 * n2 child nodes but only n1 + n2 evaluations to memorize. Consequently, during backpropagation, we have mainly 2 tables to update for each player (sum_scores[NB_ACTIONS_MAX] and nb_visits[NB_ACTIONS_MAX]) and a common array of pointers (childs[NB_ACTIONS_MAX][NB_ACTIONS_MAX]).
Remark : decisions are not completely decoupled (unlike in the case where a tree is created for each player). The choices are decoupled at a given depth. But at the next depth, the choice of an action is influenced by the opponent’s previous choice, reflecting the reality of the game.
My implementation on Xmas Rush
-
Selection :
The selection method must handle the exploration/exploitation dilemma, i.e. the balance between the width and depth of the tree.
I used the (classic) UCB1 formula. It contains an essential parameter to tune (it is even the only parameter in the basic MCTS) generally noted C. 0.3 is often a good first choice for evaluations between -1 and 1. I chose C = 0.05 for the deep course. -
Expansion :
I used the decoupled variant, described above. Legal actions considered:- for a PUSH turn: the 28 legal pushes
- for a MOVE turn: the accessible cells (limited to 28 maximum to keep the same node tables)
-
Simulation :
According to the last action played during the selection-expansion:
-for a PUSH, evaluate the current position (no additional action)
-for a MOVE, play one additional push for each player according to the following heuristics: try 5 pushes at random, keep the most promising.
Evaluation function for a player : 0.1 * the number of quests retrieved + 0.001 * the number of accessible cells -> score between 0 and 1 most of the time.
Global evaluation : evaluation for me - evaluation for the opponent + bonus/malus “deadlock” (if the game is locked AND if my first push caused a lock -> bonus if the situation is favourable to me / malus if unfavourable) -> score between -1 and 1 most of the time.
Remark : after a push, my simulation validates all accessible quests regardless of distances (approximation to limit the simulation complexity).
This scoring function easily distinguishes a promising push. It is not true for moves. This is the reason for the push played systematically after a move.
This scoring function also produces significant deviations in the case where some quests are accessibles but very small if not. That’s why the C value needs to be so small. -
Backpropagation:
I used the decoupled variant, described above.
Why does it work?
Let’s take a simple situation of Xmas Rush to try to analyze the behavior of the algorithm : let’s assume that we have 2 “killer” actions (2 different pushes allowing to grab the final quest).
Suppose that one of them is selected during the Selection phase: if the opponent’s selection is inappropriate it leads to a good evaluation.
Then, at the next iteration, the corresponding node will be selected again (because its score is now higher).
At the same time, the score of the opponent’s action is decreased. After a few iterations an action that anihilates our murderous thrust is found.
- In a sequential algorithm that means <<the opponent can annihilate our action, it’s not a good move>>.
- But here, as the score is reduced, our Selection will choose another action and at some point it will choose the other killer move.
The same process will take place and sometimes the opponent will choose the action to react to the killer’s first push, sometimes
he will choose the action to react to the second killer push (note that he cannot select effectively because he is not aware of our selection).
- As a result, the probability for these killer pushes to win in the simulation phase can be as high as half. Hence their evaluation
will remain high. In the long term, the probability for each to be played will be 1/2 (as for a human choice in the same situation).
Bonus (new quests) :
My simulation engine reproduces the random mechanism of new quests.
Consequently, the same node can be visited many times but the quests will not necessarily have been the same.
This way known quests will have a better chance of being met than others. Known quests contribute more to the score than others.
So there is no need to adapt the evaluation function to manage this : I  MCTS
MCTS