Ouch you are right, haven’t thought of that…editing
Finished 7th in Legend.
I used MCTS with UCT(Upper Confidence Bound 1 applied to trees).
Perform playout with almost random players and return the evaluation value of the game state after 4 or 5 turns (Move+Push+Move+Push or Push+Move+Push+Move+Push).
The evaluation value is the difference between the number of items acquired by me and opponent.
However, results of this simple MCTS is not very good, so I did the exclusion of bad PUSHes first before doing MCTS, in the following two ways.
-
At the beginning of PUSH turn, I do MinMax Search to find worst cases for all of my PUSH options. And I exclude my PUSH options that has a bad worst case.
It’s pretty effective to do MinMax first before doing MCTS, to prevent from selecting an action that has a bad worst case. Because the MCTS with random playout will pick actions with a high probability of being a good result, but that does not consider whether the worst case is good or bad. -
Also I did MCTS only 6ms from opponent side to predict opponent good actions and exclude the other actions.
This game is simple but deep, it was a good opportunity to think about exploring game trees in a simultaneous game.
Thank you for a nice contest! 
10 Likes
#5 Legend
Thanks to the dev team and CG for another fun contest !
I started with a minimax depth 1 in push turn, and then in move turn just get all the reacheable quests (if any) and then just do nothing. This got me to around #60.
Then I figured I would give Smitsimax a go since I had read MSmits article and found it very interesting.
When I started thinking about how to implement it I realized that the pushes of the rival in one step would affect the available moves in the next step, which was described by MSmits as a limitation to the algorithm. What I did to circumvent this was, first of all, a move for me is represented just as the destination tile, so like RoboStac I allocate all the 49 possible children of a push. A node of type move (4, 6) for me means: grab all the reacheable quests (if any) from closest to furthest, and then move to tile (4, 6). To determine the possible destination tiles I run a dijkstra algo for each player, where I also find the reacheable quests, reacheable items, distance and path to each reacheable tile. When I reach a move node in smitsimax I don’t select the child right away, but first I grab every reacheable quest, then I filter out the reacheable tiles from the final position and taking into account the remaining moves. Then I chose the child move node randomly at first, and then using the UCB formula.
My smitsimax was depth 4 (push-move-push-move or move-push-move-push) with only 5k-20k sims per turn (to me a sim is a full depth 4 simulation).
I struggled with performance and memory usage. I couldn’t go to depth 5 because memory would explode (too many heavy nodes), and even if I could my smitsimax probably wouldn’t converge since there would be too few simulations. For future contests I want to put more effort into the performance part since it is very important. The only mildly smart thing I did for performance was in the UCB formula:
float ucb = (score / (visits_of_child * scale_param)) + exploration_param * Sqrt(Log(visits of parent)) * (1/Sqrt(visits_of_child);
I precalculated the Sqrt(Log(visits of parent)) and (1/Sqrt(visits_of_child) in the initial turn for 1 to 1.000.000, so I don’t have to use the costly sqrt and log functions in the rest of the turns. This alone gave me a hugh performance boost that landed me in the 3rd place behind jolindien and MSmits on Friday night.
In the weekend I didn’t have much time to code. I tried to analyze some matches against the top 2, and tried some eval function tweaks, but my #5 final bot is almost the same as my Friday night one.
As usual, my eval function is fairly complex, and takes the following into account:
- Score
- Reacheable quests
- cleared_quests_this_turn * reacheable_items * 1000 / (remaining_items - 2) (I give value to this because of the probability of them becoming a quest when other quests have been cleared, and this probability increases inversely proportional to the remaining items).
- bonus for amount of roads in player tile
- bonus for number of dest tiles
- bonus for having a quest in a player tile
- bonus for ending in an edge of the map (left and right edges are worth more than top and bottom because horizontal pushes plays first).
Finally, he is the reason I didn’t have much time to code this weekend 

Merry christmas all !!
27 Likes
#17 with unusual algorithm. I don’t use any minimax or Monte-Carlo or GA, instead I used regret matching. Actually this game is Sequential normal-form game (i.e. moves played simultaniously, no hidden information, no random, round by round). Theory says you have to find Nash equilibria for each round (which is normal game) , using EV from future rounds, and just play them 1 by 1. This implies that in each game position there is no the best move which you play with 100% probabilty like in chess but some optimal probabilities for each move from Nash equilibrium strategy. And regret matching is the algorithm for such situation which requires payoff matrix and gives you approximations for Nash equilibrium strategy, more iterations you do, more accurate they are. A actually used simplification of CFR+ from state-of-the-art algorithms in this field and it converges to Nash equilibrium much faster.
I simulated 2 moves for both players (move+push+move+push+move or push+move+push+move) what I obviously can’t do without some pruning (it would require at least 729 * 729 = 0.5M game states only for pushes). So in my turn I solve game 2 times: one for depth 1, prune each of 729 pushes which is not involved in Nash equilibrium found on first game solving, then solve pruned game with depth 2. Usually all except around 3-4 moves for each player are pruned. If second game can’t be solved in time I just use results from the first game, otherwise I use probabilities from second game. This approach loses theoretical guarantee to converge to the right distribution of probabilities but depth worth it.
While theory says that you have to move with probabilities I tried always to use move with the highest Nash probability and it gave me +4 points, I don’t know why.
Second unusual thing was my tree storage. Of course I coded everything to bit logic and achieved sick performance. But I can’t measure number of simulations per turn because I store tree in a weird way. For me position consists of mutual information (field, player tiles) and player’s information (player’s coordinate, player’s items) for each player. Such player’s information of one position with player’s coordinates united by mutual items I call a PlayerContent. So at maximum 49 player’s informations united into single PlayerContent. “Position” accords to 1 mutual informaion (which is influenced only by pushes) and phisically stores mutual information and 2 arrays of PlayerContents but virtually it corresponds to all pairs of stored PlayerContents. You may think of it as I don’t store matrix but instead store names for rows and columns. I don’t store matrix of EVs but pass it in tree search. In leaf nodes computation can be significantly reduced as you estimate each PlayerContent (it already faster that naive way as you can take advantage of the fact that use store all accumulated player positions corresponding to single items layout and reuse already computed values for one connectivity component) and also you can just calc arrays est_i[] for each i from {0,1} and define matrix elements as val[i][j] = est_0[i] - est_1[j]. With all these optimizations I came down to unusual situation when bottleneck of my algorithm is not estimation of leaf nodes but solving games in their parents. And I know it is very hard to understand what I wrote in this paragraph, I also have trouble thinking about it even in my own language.
About estimate function, in addition to features mentioned in above posts I also used expected number of picked up items. For example consider a situation where you picked 2 items on first move turn and then you pushed with your opponent. And you can reach 2 not quested items out of all 5 unquested items. In this case I add 2 * 1/10 + 1 * 6/10 = 0.8 score to estimate.
Overall contest was very fun. Big number of ties sadden a bit but overall it was a great game with simple rules. And sorry for bad english
10 Likes
49th place. Early heuristics kept me around top10 till gold-legend, but then my simple search setup (+many bugs) proved to be insufficent vs. the more solid approaches (eg. mini/smitsimaxs).
Some of the highlights: fast BFS, enemy prediction, item prediction, multi-phase deadlock detection.
As most of those are already shared, instead I add my last (resort) trick, which I have delayed till the very end (so it won’t get copied). Even though yesterday I knew that it wont make a real difference for me.
It is a fun way of deadlock breaking. Weaker players (like me) are usually accept draw (kept deadlock on equal score). But for the last push turn I added a check for a break with item pick (=instant victory).
It might even be used for -1 item balance to reach draw (haven’t added that). Of course such trick wouldn’t help vs. better players at all, cause they broke tie much earlier on prediction (not by rule)
2 Likes
Tight top 10 in legend.
I began with a classic minimax though not very optimized since I was doing either Push + Move + Few Pushes or Move + Push + Move + Few pushes. Like JRFerguson, I feel like for next contests I should take more time on building performant data structurs.
I painfully reached bronze in the middle of the week, then I realized that I was pushing left when I meant to push right, bottom when I meant top… After leaving this drag I rose around 10th and hovered around this rank until the end.
I think the main update that let me stay competitive in top legend is that I switched from my paranoid minimax to a “solved” minimax. The main issue with the paranoid minimax is that when you have n actions, each contered by a different move from the opponent, you would like to have it understand they are no that bad since any of those n actions will have somehow a probability of (n-1)/n to succed. Thus, the idea is to build the whole payoff matrix (unfortunately reducing the amount of possible prunings) of each player pushes and to solve it to get the optimal strategy.
For example, using this link : https://www.math.ucla.edu/~tom/gamesolve.html, the 3x3 payoff matrix
6 6 -2
6 -2 6
-1 -1 -1 gives the optimal strategy (0.5,0.5,0)
So it’s in the end quite the same as miklla. I too had to take the highest Nash probability rather than choosing stochastically. Eventually, I found a convenient iterative algorithm to approximate the solution of the payoff matrix conveniently in linear time : http://code.activestate.com/recipes/496825-game-theory-payoff-matrix-solver/
As for the constest itself, it was really well made and I found it interesting (and sometimes exasperating!) to work on something so simple rule-wise and so hellish if you wanted to work with heuristics or understand thoroughly what your bot was thinking.
6 Likes
Hi,
Finished #16 Legend
Today, another episode of “how to suck at chosing an algorithm”, season 12 :
At firt sight, minmax seemed like an obvious choice to me, but after finishing implementing the engine and calculating how many sims I could afford, and watching a few of the top games, I though this would require depths I could never reach so I dropped the idea in favor of a poorly-written search :
MOVE turns :
Simulate every MOVE PUSH MOVE PUSH MOVE just for me, ignoring the enemy.
The first MOVE pass is only 1 pick sequence, from closest to further reachable active item, and then 1 legal move per reachable cell from the last picked item.
To save some sims in the latest plies, I used an idea pb4 told me (thanks!) :
Mark the cells that I can reach and then simulate every push. For each post-push state, start a floodfill from every marked cell. Select the best post-push area, i.e. the one that maximize : nbItems * 1000 + reachableCells.
PUSH turns :
Minmax the PUSH combinations, then explore MOVE PUSH MOVE next turns, ignoring the enemy.
iirc this algorithm put me top 5 mid-contest for a short period after spending a few days fixing some bugs.
Full of confidence, and knowing that enemy prediction sucked with my current approach, I wrote a minmax, thus contradicting my early-contest thougts. Classic minmax implementation, with killer-move and hash-move (Using delta move, not full-state move, because I’m lazy. Delta move is a zobrist hash where you start from an empty hash at the beginning of the turn, and then XOR each move, having a zobrist entry per move, per depth), reaching depth 6 to 10 (1 depth = 1 action from 1 enemy, so an actual game turn is depth 2).
This version was poorly optimised (between 100k and 250k explored nodes) and encountered previously-mentioned issues regarding simultaneous actions.
In a last attempt, I mixed both approaches : use my minmax on MOVE turns, and my former search on PUSH turns. The result makes no sense but it had the best benchmark results…
Thanks to the creators : this game was really well designed imo, one of my favorite for sure.
You could argue about deadlocks and ties but I think this opens a few strategies options (how and when break those deadlocks).
See you at the next CC 
12 Likes
Legend 15th, C#.
Very good game, though too hard to start with. A move command with position would make the start a whole lot easier 
Also, agree with Magus on the tie breaks.
Bronze, friday
Heuristics, push me/item position closer, BFS to first item.
1st, saturday night
Full simulation (had 30 unit test to verify everything ) with a montecarlo based search. This solution was too linear, but was good enough early on.
I randomized an array of doubles then picked actions based on these each round. Simulated the enemy the same way and played myself vs his best + a dummy version.
- Push: Pick push nr (int)(val*28)
- Move: Assume I can reach all spots found by DFS and fetch all items on the way. (rarely more than 20 availiable steps)
Busy week
Only had time to play with params, but never had a chance to fight euler anymore 
Thursday
Converted my solution into some kind of Smitsimax, like many others…
As a start I only used UCB on the first move/push, every other action was random, ended using UCB for pushes only.
Move was picking the best move found by a simple eval, this was later changed to 90% random and 10 % best.
Every round is done with a decay of 0.99 and I simulated MOVE-PUSH-MOVE for move and PUSH-MOVE-PUSH-MOVE for push.
Eval of possible positions:
- 1000 each quest.
- 2 for each possible tile
- 5 for other items
Eval of selected position:
- 2 for each open direction
- -2 if 1 from a quest (beeing 1 from a quest you haven’t picked makes it harder to pick(?)
- -3 if X or Y is equal to quest
My move still assumes it can reach every spot, and my last submit was 9:59:40, which turned out OK 
GG.
5 Likes
Hi there,
Thanks to the CG Team and the creators of this contest ! It’s my second one after Locam and I learned a lot, I also have a preference for board games so it was perfect
My PM is not really about my implementation as it’s trivial compared to what legend did but more of my progression as I reached #30 in Legend with depth 1-ish.
I started prototyping in JS as I’m used to for puzzles and got to gold with it, I just implemented a DFS similar to what YannT did and for every push I could make, run an eval on every path possible, then getting the best path for that push and so on for all push.
Since it was just heuristic based, I had to do more to progress in gold. As I was getting serious I switched to C++ and learning it at the same time. First thing was to generate 28*28 pushes then I understood that it must be what they mean by MinMax xD (well i think it is ? My first time using this algorithm), for each of my push try 28 opponent possible keep the worst eval and keep the best one of my pushes. Second thing was to take into account the opponent because even if you think you are playing your best move maybe the situation is even better for the opponent, so basically it was just score = eval(me) - eval(opponent). Last thing was to handle deadlock.
In the end I had a working MinMax with an eval very similar to what JRFerguson did, on push turn I was doing push+move and on move turn just move… I think it’s the little things that got me this far without any real depth, good eval (taking all items, predicting the best tile to end the move including future items if I’m second), good gestion of deadlock (don’t break if winning, break sooner if I’m losing and limit the push of the opponent to the one I’m giving up, break later if in draw and only if my next move is better than the opponent).
I tried on Sunday to increase the depth push+move+push+move and move+push+move, had a working sim but not fast enough (not enough time to code and I’m not good enough with C++), with a timeout limit it was not exploring all the way so performed worse than my previous work that I ended up submitting.
Also had a good time on the chat as it really helps with motivation (especially during the promotion to legend )
Congratz all
4 Likes
I wrote my post mortem here: https://tech.io/playgrounds/38549/x-mas-rush-post-mortem
Congratulations for a well fought win Jolindien!
It was great fun. Had to adjust my expectations a bit after first hitting nr 1 by a wide margin, staying that way for a day or two and then being surpassed by Jolindien. This is my personal best though and I am very happy with it. Nice to see so many people experimenting with Smitsimax. It was pointed out to me by DrBloodmoney that this algorithm already existed before I “invented” it.
It’s ok if you keep calling it Smitsimax, but the official credit goes here or something prior to this: https://www.researchgate.net/publication/224396568_CadiaPlayer_A_Simulation-Based_General_Game_Player
If you want to dive into it, find out for yourself There is so much to learn about search algorithms, you’re bound to reinvent the wheel a few times because it’s easier than keeping track of all the knowledge that’s out there.
Many thanks to the creators of the game. I don’t agree with the criticism about deadlocks. I was able to fend them off most of the time. It was part of the challenge in my opinion. This game is perfect for a bot contest. Brilliantly executed!
EDIT: I will share a BFS article at a later date. Fast BFS was very important in this contest, but I want to share the knowledge properly, in its own tech.io playground.
24 Likes
Rank 18.
I promised myself to write a PM once I reached top 20, so here goes.
This will not just be what algorithm I used but also about how I approached the contest - my apologies for it being so long.
My first contest - GitC - I didn’t get past silver, so my goal back then was to reach gold, which I did 4 contests later. Then the goal became to reach legend, which happened a few contests later in BotG, and wouldn’t happen again until LocM. Then the goal became to reach top 20, which is finally accomplished!
Friday - Getting out of the woods (Wood 2 -> Bronze)
Right before the contest I prepared a git repository and a Visual Studio C++ Project, a dummy main.cpp and a Makefile. I always commit each submit, and with git commit --amend I note the rank that it got.
Wood 2
It took me about 3 hours to write a bot worthy of submission, which is significantly longer than in other contests. However, I had to spend far less time changing data structures and IO parsing for higher leagues so it paid off to spend some extra time getting things right from the start.
My grid (the game board) is a simple 1D array, where the low 4 bits of each cell correspond to the tile directions, and the 4th and 5th bit indicate a questable item for players 0 and 1 (later I would also use bits 6 and 7 for non-questable items).
The first submission was a simple BFS to the item on MOVE turns, and a random PUSH turn, which got me rank 17 in wood 2. Next I checked 28 PUSH moves and evaluated them with the BFS, falling back to a random push if no item could be found. This lowered the bot’s rank to 25. Then I found out that MOVE doesn’t wrap, and that I forgot to update the player position in the PUSH sim. Fixing this lowered my rank even further to 37. Time to debug.
After having watched Recurse’s stream during LoCM where he implemented a BitStream to serialize the state into a base64 string, I finally took the time to write one, and it has saved me tons of time since. Simply copy-paste the string into VS and press F7 to debug a specific turn!
I added it here and started debugging, and found out that the negative coordinates on items were overwriting the wrong memory… Once I fixed this the bot passed to wood 1.
Wood 1
Updating the bot to honor the new rules took about an hour, mostly because I had to skim the referee to find out what all the quest names were, to that I could store them as ints instead of strings. The only change I had to make was to only mark the items that were questable instead of all of them, which got me to rank 5 in bronze/global - a promising start.
Bronze
Now I had to figure out how to pick up more than 1 item at a time. I decided on a quick hack for now and continue the BFS until I had picked up 3 items. I also added breaking a deadlock if I was behind, and expanded the search on the MOVE turn to check all 28 PUSHes for each reachable tile, which landed the bot at rank 3, and I called it quits for the day.
Saturday - Bronze
On Saturday I found the bot had drifted down to rank 15, and I spent some time fixing the BFS so it would actually pick up all items, since it wouldn’t backtrack out of dead end alleys. It experienced some buffer overflows because the paths would get longer than 49 cells - bitstream to the rescue. I also added a BFS specific for searches where paths aren’t important - just how many items and tiles.
This got the bot back up to rank 8.
Sunday - Monday - Bronze -> Silver
As people kept improving, the bot had fallen down to rank 20, and I spent all day implementing a full PUSH search, which, due to bugs, landed it mostly around rank 70-100; it was hard to get back into top 40, and I finally disabled most of it and left the bot at rank 38, which was sufficient to get it to promote to Silver the next day, landing on rank 28.
The full PUSH search mentioned consists of all possible combinations of ‘PUSH-PUSH’ followed by a BFS counting reachable tiles and items for both players - henceforth ‘PUSH-PUSH-MOVE-MOVE’. I was ignoring the row-before-column rule and duplicates, for the time being. For each of the BFS pairs I added a bonus for holding one of one’s own questable items, and subtract them to get one number which I put in a score matrix, rows being my moves, columns being the opponent moves, which would come in handy later. For now I just summed all the values in a row to arrive at a score for each of my moves.
On monday I fixed the PUSH-PUSH sim simply by swapping two for-loops, which got the bot up to rank 6, so my sunday wasn’t wasted after all.
Tuesday, Wednesday - Silver -> Gold
The bot was pretty stable around rank 10. I improved the PUSH-PUSH search further so it would honor the row-before-column rule, and not count any duplicates. This, and adding scoring non-questable items in the BFS didn’t have much impact.
On Wednesday I added another depth to the PUSH turn: one PUSH-MOVE-MOVE turn (since my PUSH-PUSH-MOVE-MOVE only took about 0.3ms) and averaged the scores. Even though a single push yields a board state that cannot happen, averaging the scores gives a decent impression anyway. So now I had a PUSH-PUSH-MOVE-MOVE PUSH-MOVE-MOVE, doing about 42k PUSH sims and 84k BFS, which took anywhere between 6ms and 23ms, depending on how the size of reachable areas in the BFS. This was clearly too slow to also apply to each reachable tile in the MOVE turn, so I kept that at PUSH-PUSH-MOVE-MOVE.
Thursday - Gold
I found the bot promoted to gold, rank 15, and started working on a minimax scoring scheme. For each of the bot’s moves, I’d iterate all the opponent’s moves and find the lowest score, and then pick the highest score (and corresponding move) out of those. This got the bot back up to rank 10. My weights for scoring were:
SCORE_ITEM = 1.0 // BFS picking up a questable item
SCORE_ITEMTILE = 0.5 // holding a questable item on playerTile
SCORE_POTENTIAL_ITEM = 0.4 // BFS finding path to non-questable item
SCORE_REACHABLE = 0.1 // BFS reachable tiles
SCORE_SCALE_FINALDEPTH = 0.5 // the final depth is odd, so don't score it as highly
After changing SCORE_ITEM to 10.0, the bot rose to rank 5 - that extra 0 paid off!
Friday - Legend
The bot had promoted to legend, rank 8, and was slowly drifting down to rank 12. I had to fix the MOVE turn where it would consider all reachable tiles to simulate the PUSH turn, instead of only those that were reachable within 20 steps. I also changed the scoring on the MOVE turns to not use the minimax scheme, and this gave better results. I tried some other things, like encouraging a deadlock if I was ahead, but this didn’t work out. I left the bot at rank 8.
Saturday - Legend
I added caching to the PUSH-PUSH-MOVE-MOVE layer, so that I could also do the PUSH-MOVE-MOVE in a MOVE turn without doing the PUSH-PUSH-MOVE-MOVE twice. The first loop would calculate all PUSH-PUSH-MOVE-MOVE combinations as usual, then sort them by score, and while there was time left, augment the scores by calculating the final depth. Even if it didn’t have time to complete 1 or more turns in the final depth, nothing would be lost, and if it completed more than one the bot would have a better idea on which was better. MOVE turns now used 40ms instead of 0.3ms, and did about 150k-200k PUSH sims and 300k-400k BFS. Clearly enough to try another approach, but, I wouldn’t have much time on Sunday so I chose to stick with this approach.
I was able to maintain rank 8 for a good part of the day, and started working on being able to use brutaltester - something which I usually do in the first few days, but I didn’t see the need because the bot was performing unexpectedly well. Luckily all I had to do was copy CommandLineInterface.java and add the missing parts to the pom.xml, both from the LoCM brutaltester-compatible referee. I modified the CG game engine to allow for higher timeouts, since the way that’s calculated has changed (during high load some bots will time out because they don’t get enough CPU time) and adding deadlock detection to the referee to cut such games short.
The rest of the day was spent tweaking scores, and as people kept improving, the bot slowly drifted down to rank 18…
Sunday - Monday morning - the final push
I didn’t have much time on Sunday and was pretty tired already so after adding quest prediction I didn’t come up with new ideas, and spent the evening running sims trying to find that ‘magic number’, to no avail (with 1 exception :SCORE_REACHABLE = 0.6). I abandoned brutaltester and went experimenting in the online IDE. Since a lot of people were submitting and improving it was getting pretty hard to tell whether a submit
was better or not. I did find some numbers that consistently beat other players, but it would lose against others, and depending who was submitting, the results would vary wildly. The best submits would have the bot end up at rank 17, but an hour later it wouldn’t pass rank 24.
Only Four hours to go, and ending up in top 20 seemed to become most unlikely…
Then, in the chat I was reminded of a feature that I had planned but forgot to implement (thanks EulerscheZahl!): giving a bonus to ending a MOVE turn on a spot where the next PUSH turn would collect that item. Adding that got the bot up to rank 13, and at 7 AM I finally called it quits. It turned out to be enough!
Thanks everyone for a great contest!
11 Likes
Can I have some questions to those who used minmax? I failed to implement it due my low experience with this method.
- Did you run scoring function only on leaf nodes or after each depth?
- Is it correct sequence of simulation for push turn?
My PUSH, Opponent PUSH -> My MOVE, Opponent MOVE - > My PUSH, Opponent PUSH… - I don’t know how to use full time limit with minmax - is Iterative deeping the only method for this?
I found it very Interesting that many different player ended(?) up similar heuristical values (me too!)
like scoring:
-100 for item
-1 for accessible tiles
-5 for item on players tile
or 5th turn tie breaking
I used lower values for scoring:
- 1 for obtaining a quest item
- 0.01 for each accessible neighboring tile
- 0.1 for holding a quest item
- 0,1 bonus for being pushed into a quest item
avoid deadlock after 5th repetitive PUSH
I started out with bonus for holding a quest as well, but bizarrely went even higher when I removed the rule… Getting these score functions right is quite hard.
My feedback.
A really good contest (one of te overall best one).
Maybe something on draw would be nice as the ko rule on the go game.
The other drawback was very few developpers competing.
I reached another top-100 (72th), I’m quite happy, I don’t have too much time for contest, thus I cannot compete on top-20.
I go on NegaMax (evaluation = myEval - oppEval) very fast. Depth 1 only as I always have performance issues as I’m using lot of Linq statement in my C# code.
I hope this contest will make reflexion for other guys who want to create one ; there are many cool abstract game to implement as contest.
4 Likes
I ranked 3rd, which is the best ranking I’ve ever had in a CodinGame challenge! 
To be honest, this was one of my favourite contests (and I don’t say that only because of my very good ranking ). The rules were simple and easy to understand, and the game was interesting! I think there were only two minor issues: maybe the game was too difficult to enter (even if it was definitely not a problem for me), and a lot of games would end up with a tie.
At the beginning of the contest, I first decided to use a negamax with a simple eval, because I thought it could work pretty well. I managed to go up to mid-gold with this negamax.
After this, I saw that MSmith was ranked 1st, and remembered reading his article about the Smitsimax, so I decided to implement this algorithm. I just had to copy-paste the implementation I use for Coders Strike Back, and tweaked it to make it compile. I was really surprised with the results I got, because it was better than my old AI on the first try. After a few bug fixes and optimisations, I was finally able to enter the Legend Ligue. Then, I finished to code the last features, correct the last bugs, optimize the code, and tadam! I ranked 3rd .
My evaluation function was really simple: I only took into account the number of quests each player has completed.
My exploration was depth 4 (4 actions per player).
I thought I should have started to code earlier, because at the end of the contest I still had a lot of things to do: I didn’t have the time to check the correctness of my code, nor to change the exploration coefficient, I let it to sqrt(2). What’s more, my code wasn’t really fast: I was only able to call the exploration function about 10k times a turn.
Here is the evolution of my ranking:
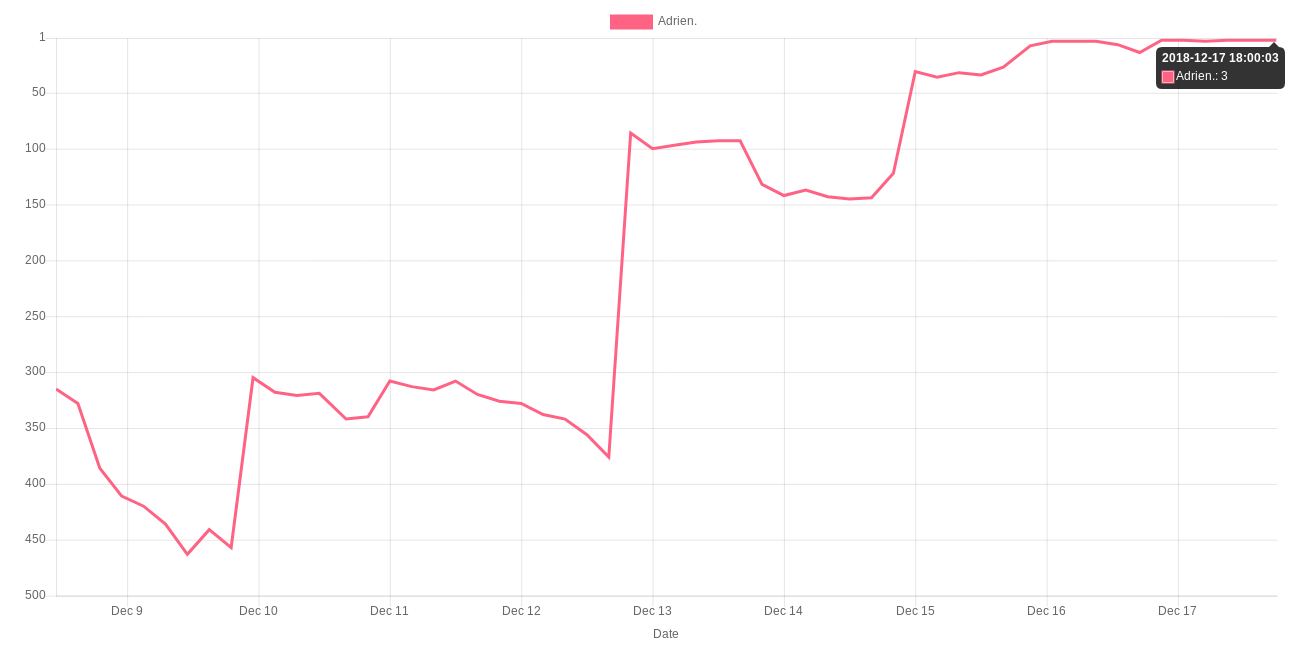
Merry christmas everyone!
12 Likes
Legend 1st, C++.
Above all, a big thank to Chimney42 , Iuliia , rnkey et Tzupy : that was a great challenge!
The main originality of the game was undoubtedly the importance of simultaneous actions.
Thus my priority was to find an algorithm that could meet this constraint. Decoupled MCTS seems to be ideal.
As a bonus, it also allows to take into account the random part of the game (the appearance of new quests).
I love MCTS
The Monte Carlo Tree Search (MCTS) algorithm consists of 4 steps (selection, expansion, simulation, backpropagation) as shown in this figure.
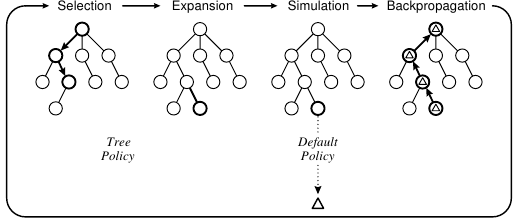
In its basic form, the simulation step evaluates the value of a position by playing random moves. It must be admitted that in this form the MCTS has not been very successful.
But in recent years a very active community has been offering variants that exploit the specificities of the problems encountered.
The most famous example is the DeepMind algorithm for the Go where an MCTS uses 2 neural networks in the simulation phase (one to evaluate the position and the other to generate “better” random moves) [ref].
MCTS is no longer rigid and becomes a very flexible canvas that leaves a lot to creativity.
It also adapts very naturally to many situations (simultaneous move games, multi-player games, puzzles…).
That’s why I use the MCTS more and more frequently on Codingame: Ultimate Tic Tac Toe (2 players), Tron (4 players), Mars Lander (optimzation)…
Note: I do not distinguish between MCTS and what could be called UCT (UCB applies to Trees).
Decoupled MCTS
Decoupled MCTS is the version for simultaneous move games [ref]. This variation modifies the structure of a node as in the following figure:
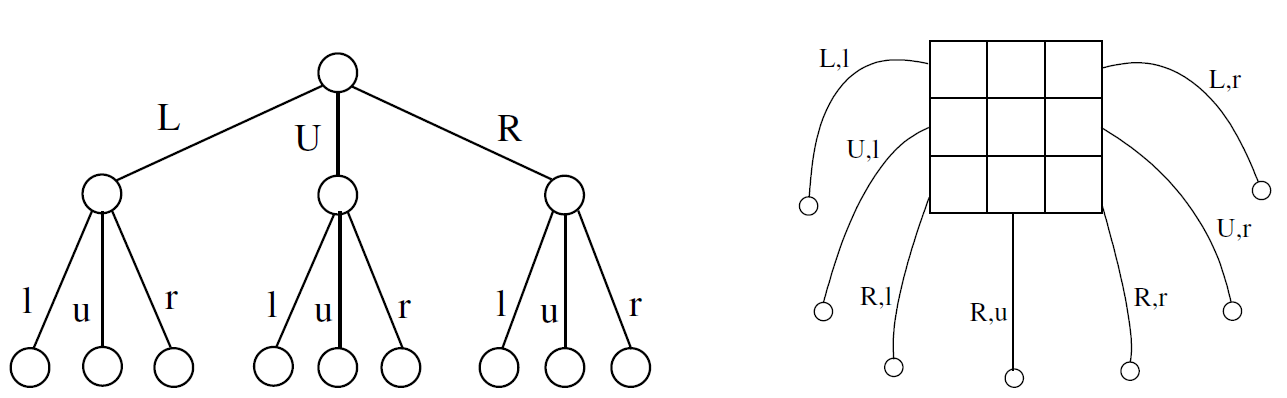
In the sequential form (left) each node represents the child node of the corresponding move (L,U,R for Player1 and l,u,r for Player2). In the decoupled form (right) each joint move leads to a child node from a combination of moves for Player 1 and Player 2 (only 7 of the 9 joint moves are shown).
In this variation the selection of a node is done through the simultaneous selection of an action for Player1 and an action for Player2. The term “decoupled” reflects the fact that (in a given node) the choice of the Player2 does not depend on the choice of the Player1.
Let n1 and n2 be the number of actions of Player1 and Player2. Then there is n1 * n2 child nodes but only n1 + n2 evaluations to memorize. Consequently, during backpropagation, we have mainly 2 tables to update for each player (sum_scores[NB_ACTIONS_MAX] and nb_visits[NB_ACTIONS_MAX]) and a common array of pointers (childs[NB_ACTIONS_MAX][NB_ACTIONS_MAX]).
Remark : decisions are not completely decoupled (unlike in the case where a tree is created for each player). The choices are decoupled at a given depth. But at the next depth, the choice of an action is influenced by the opponent’s previous choice, reflecting the reality of the game.
My implementation on Xmas Rush
-
Selection :
The selection method must handle the exploration/exploitation dilemma, i.e. the balance between the width and depth of the tree.
I used the (classic) UCB1 formula. It contains an essential parameter to tune (it is even the only parameter in the basic MCTS) generally noted C. 0.3 is often a good first choice for evaluations between -1 and 1. I chose C = 0.05 for the deep course. -
Expansion :
I used the decoupled variant, described above. Legal actions considered:- for a PUSH turn: the 28 legal pushes
- for a MOVE turn: the accessible cells (limited to 28 maximum to keep the same node tables)
-
Simulation :
According to the last action played during the selection-expansion:
-for a PUSH, evaluate the current position (no additional action)
-for a MOVE, play one additional push for each player according to the following heuristics: try 5 pushes at random, keep the most promising.
Evaluation function for a player : 0.1 * the number of quests retrieved + 0.001 * the number of accessible cells -> score between 0 and 1 most of the time.
Global evaluation : evaluation for me - evaluation for the opponent + bonus/malus “deadlock” (if the game is locked AND if my first push caused a lock -> bonus if the situation is favourable to me / malus if unfavourable) -> score between -1 and 1 most of the time.
Remark : after a push, my simulation validates all accessible quests regardless of distances (approximation to limit the simulation complexity).
This scoring function easily distinguishes a promising push. It is not true for moves. This is the reason for the push played systematically after a move.
This scoring function also produces significant deviations in the case where some quests are accessibles but very small if not. That’s why the C value needs to be so small. -
Backpropagation:
I used the decoupled variant, described above.
Why does it work?
Let’s take a simple situation of Xmas Rush to try to analyze the behavior of the algorithm : let’s assume that we have 2 “killer” actions (2 different pushes allowing to grab the final quest).
Suppose that one of them is selected during the Selection phase: if the opponent’s selection is inappropriate it leads to a good evaluation.
Then, at the next iteration, the corresponding node will be selected again (because its score is now higher).
At the same time, the score of the opponent’s action is decreased. After a few iterations an action that anihilates our murderous thrust is found.
- In a sequential algorithm that means <<the opponent can annihilate our action, it’s not a good move>>.
- But here, as the score is reduced, our Selection will choose another action and at some point it will choose the other killer move.
The same process will take place and sometimes the opponent will choose the action to react to the killer’s first push, sometimes
he will choose the action to react to the second killer push (note that he cannot select effectively because he is not aware of our selection).
- As a result, the probability for these killer pushes to win in the simulation phase can be as high as half. Hence their evaluation
will remain high. In the long term, the probability for each to be played will be 1/2 (as for a human choice in the same situation).
Bonus (new quests) :
My simulation engine reproduces the random mechanism of new quests.
Consequently, the same node can be visited many times but the quests will not necessarily have been the same.
This way known quests will have a better chance of being met than others. Known quests contribute more to the score than others.
So there is no need to adapt the evaluation function to manage this : I  MCTS
MCTS
40 Likes
Thanks a lot for your explanations! Just 2 quick questions:
- Do you copy the state in the node after the actions have been applied, or do you replay them during the selection phase?
- Can you give us an rough estimation of how many times you visited the root node?
1 Like
I don’t copy the state in the node. Maybe it could improve performance
(I didn’t try in Xmas rush). But the feature about new quest would no longer work.
I visited about 10k the root node. This could be significantly improved.
1 Like