Feel free to send your feedback or ask for some help here!
Game link: Coding Games and Programming Challenges to Code Better
Don’t hesitate to check out the topic for the corresponding contest: Summer Challenge 2024 - Feedback and Strategies
Feel free to send your feedback or ask for some help here!
Game link: Coding Games and Programming Challenges to Code Better
Don’t hesitate to check out the topic for the corresponding contest: Summer Challenge 2024 - Feedback and Strategies
For some reason there seems to be a bug where my score doesn’t increase in the viewer. When checking the variable score_info, it seems to show boss2’s score instead of the player’s score as changes in score_info are reflected in boss_2’s score in the viewer, while my score continues to be 0. The only time my score increases is when 2 mini-games reach game-over at the same time, and that’s when my score starts to increase normally. But because of all this, no matter how many medals I get, I will always be placed 3rd and can never win against the bosses.
The referee is OK. The bug is on your side or you may have not noticed that the score is the product of the minigames scores. If you miss medals in one of them, the score stays at 0. Share a replay of one of your games.
Anyone any wisdom to share regarding the Skating minigame? My bot currently is significantly better if I just let Skating do random moves (or, based on the other game’s preferences), rather than influencing the decision based on simple Skating decisions (2-3 steps if risk <3 otherwise 1 step). Or, let me rephrase: are there Gold- or even Legend-ranked players that completely ignore Skating?
Edit: lol, while typing this I actually just reached Gold. The change that bumped me from Silver 100-150 to Gold was to ignore the skating minigame. My question remains: what are opinions regarding including or ignoring the skating minigame in move selection?
Apart from ignoring the Skating minigame, what have you done to move Gold? I’m already ignoring Skating and my rank is fluctuating between 40 - 50 in Silver. I never implemented simulation or search algorithm for any bot programming challenge, my bot is based on very simple heuristic. This time it’s very hard to getting insights from the replays so I couldn’t do much with the heuristics as well.
It might have been a lucky commit that brought me just over the edge into gold. As for the things I have done: my bot is still fully heuristic (I also never got into simulating and search algorithms for any contest). Per minigame (Hurdles, Archery and Diving) in a given turn I decide what the best move(s) would be. Furthermore, I check for guaranteed win/loss/silver situations: if that is the case for a certain mini-game, I simply give as “best moves” all of the moves.
Then I weigh the given mini-game moves based on the gold/silver status: giving extra weight to moves connected to a minigame in which I currently have lowest points. That is what brought me into gold.
At the moment I brought skating back in; I upgraded my skating move selecting, and it is currently such that it gives me a slightly better result when I include it versus not. Still, it does not matter a lot. I guess skating moves have such high variation across turns that you either need a very good skating move selector, or otherwise just leave it up to the move variation that comes from the other games.
Hello all, I need help with my MCTS idea. I’ll try to explain it as clear as I can.
I want to use classical MCTS adapted for this 3 player simultaneous game. I’ve already used this approach in another game and it works really well: Di_Masta Spring Challenge 2021 Puzzle. And I know that other players also use it like this: Magus Spring Challenge 2021 Post motern.
The main idea is on each turn first to prepare for the MCTS. Then to run as many MCTS iterations as possible in the given time frame. After the search I choose the best child of the root Node for the bot action.
The Tree Data Structure:
My Tree is just a very big linear array of Nodes and each Node is accessed by its index. I keep track, which Node is the root of the tree. I visualize the tree like this:
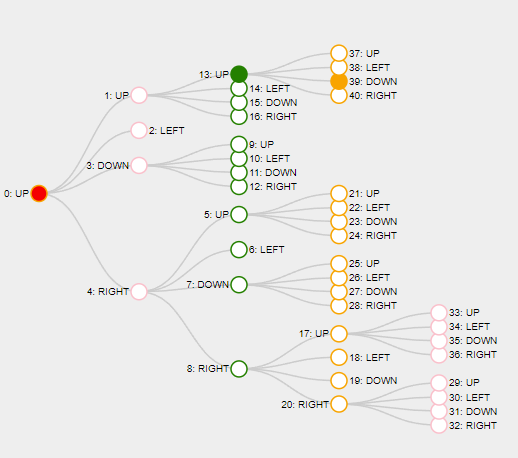
Each depth of the tree represents a move for the corresponding players:
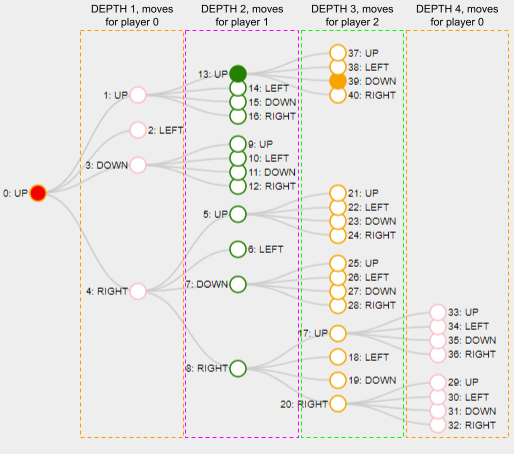
The Node:
My Node stores a game move, the index of its parent Node, the indices for the children, depth, visits count and win score.
The Game State
I store the game state separately. It could be simulated using a sequence of moves and it could be copied, but it’s not directly stored in the search tree.
Execution:
On the 0th turn there isn’t much to prepare I just create a root Node with an invalid move. Then I start to loop for MCTS.
On each MCTS iteration:
I perform the standard SELECTION; EXPAND; PLAYOUT and BACKPROPAGATE steps as follows:
SELECTION
Starting from the root Node I traverse the tree and at each depth I choose the child with the best UCT value:
float Node::uct(const float parentVisits) const {
float value = MAX_FLOAT;
if (visits > 0.f) {
const float winVisitsRatio = winScore / visits;
const float confidentRatio = UCT_VALUE * (sqrtf(logf(parentVisits) / visits));
value = winVisitsRatio + confidentRatio;
}
return value;
}
If I have several children with MAX_FLOAT uct (not visited yet) I choose one of them at random, which I’m not sure is the CORRECT approach?
On the 0th turn and the 0th iteration the root does not have children, so it’s the selected one.
As I traverse the tree I gather the moves in a sequence from the root to the leave. Then I use this sequence for simulation from the current game state. If the sequence length is not divisible by 3 I ignore the last 1 or 2 moves, which I’ll take into account on the playout step.
EXPANSION
Then I expand the last selected leaf node with 4 children for each move.
PLAYOUT
I select one of the new children from the expansion and I simulate a random game from it onwards until I reach GAME_OVER on all 4 mini games. For the first set of moves if the selected node depth is not divisible by 3 I choose moves form it’s parents, which I’ve ignored in the selection phase
BACKPROPAGATE
When the 4 mini games have reached GAME OVER in the playout phase I decide the winner by calculating the whole game score and return the winner index. Then at each node on the path I check the depth and the winner index and increment the visits:
void MCTS::backPropagate(const int selectedNodeIdx, GameState result) {
int currentNodeIdx = selectedNodeIdx;
// Each child has bigger index than its parent
while (currentRootNodeIdx <= currentNodeIdx) {
Node& currentNode = searchTree.getNode(currentNodeIdx);
currentNode.incrementVisits();
if ((currentNode.getDepth() % PLAYERS_COUNT) == static_cast<int>(result)) {
currentNode.setWinScore(currentNode.getWinScore() + WIN_VALUE);
}
else if (GameState::DRAW == result) {
currentNode.setWinScore(currentNode.getWinScore() + DRAW_VALUE);
}
currentNodeIdx = currentNode.getParentIdx();
}
}
When the time for the turns ends I stop the search and get the child of the root with the best win score
Afterwards on the next turn I try to reuse the whole tree by checking the read game state and figuring out the opponent turns.
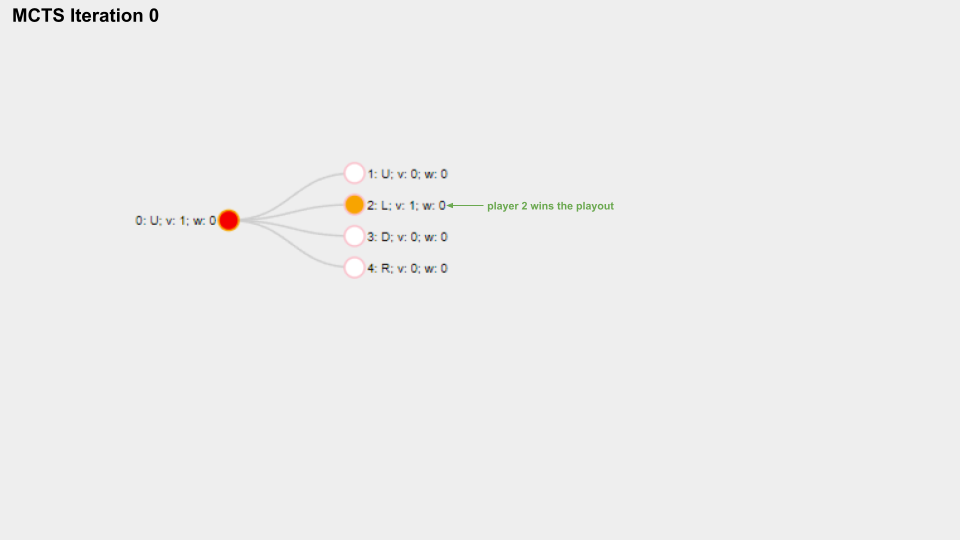
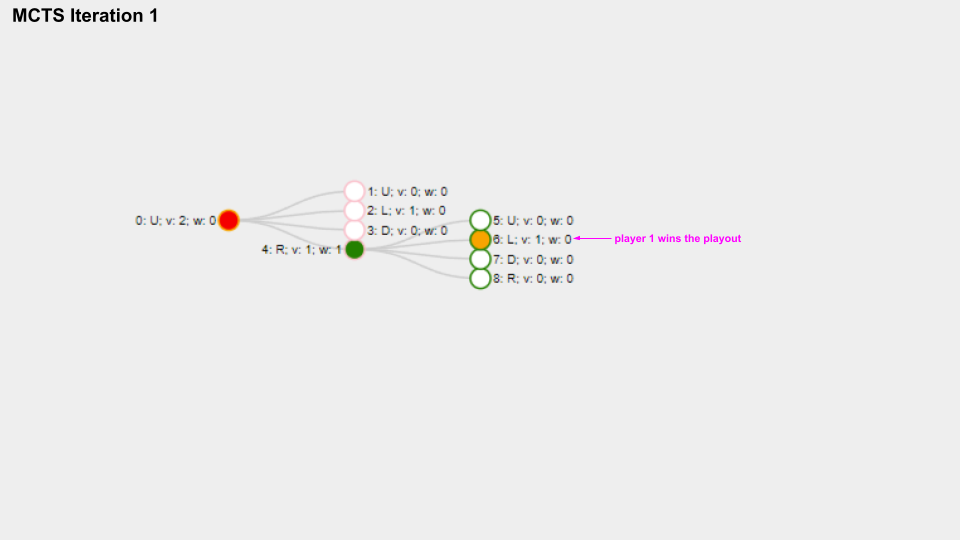
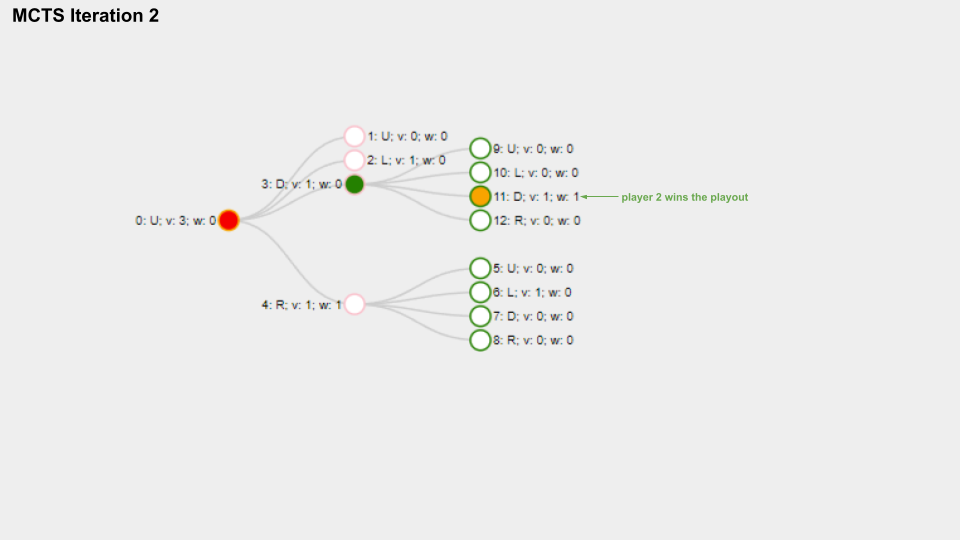
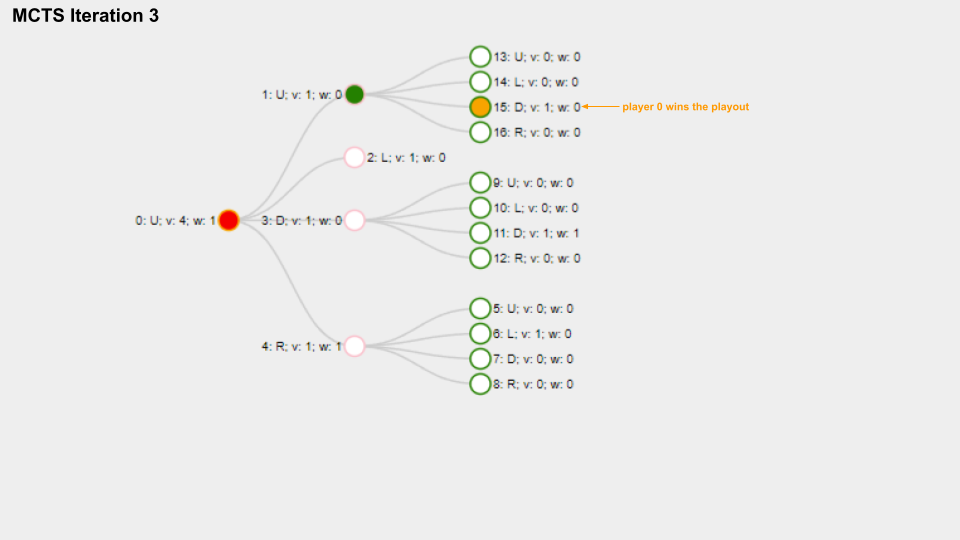
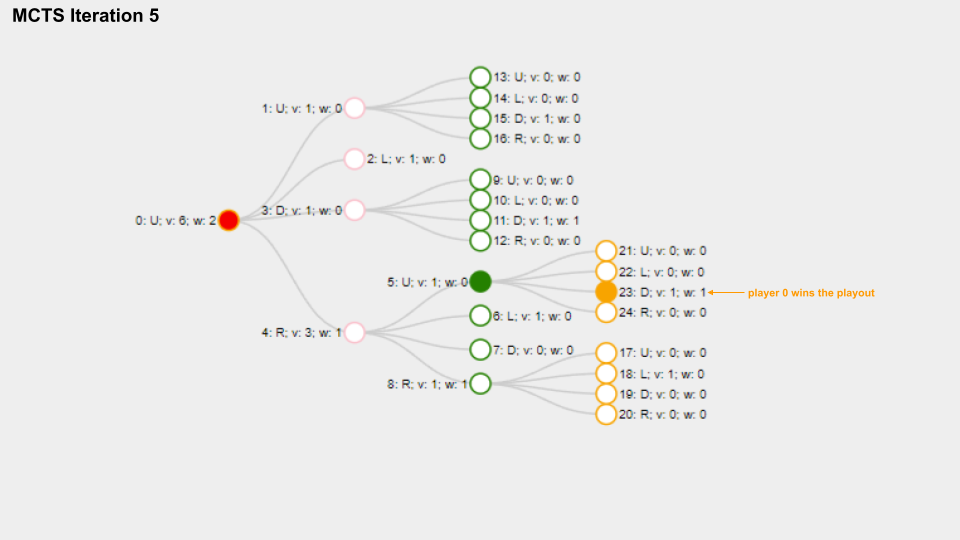
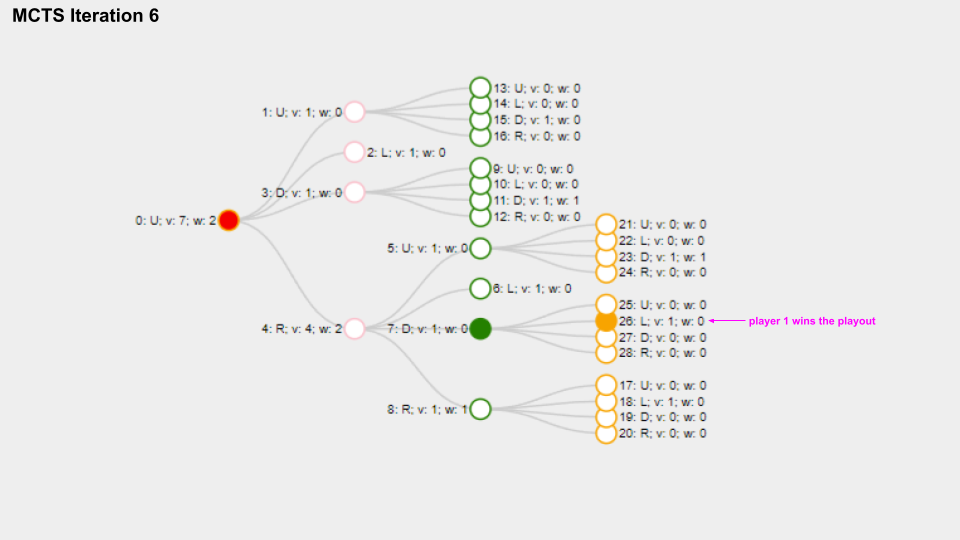
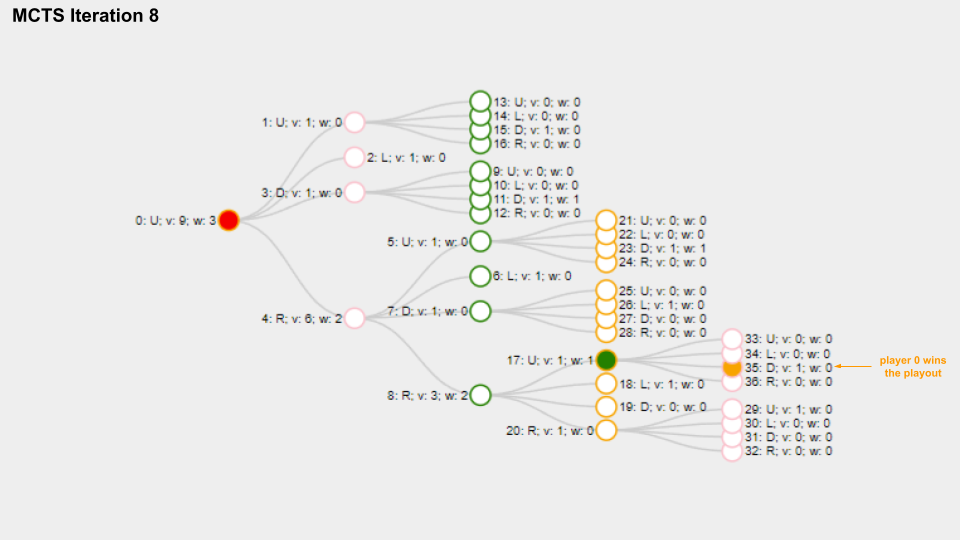
And here is a slide deck of 10 MCTS iterations.
With solid green circle I mark the Node which is selected on the selection phase, with solid orange color I mark the Node chosen for the playout phase.
The name for each Node is composed like this “Index: Move letter; v: Visits count; w: Win score”
I know this approach is not something impressive, I believe that is has potential, but obviously I’m making something very wrong could someone suggest me what to try? At the moment I cannot even win against the bottom Gold bots even though I’m making around 150K MCTS iterations on the first turn and 10K on the second, which I think is not bad.
Your backpropagation code looks fishy to me: you should backpropagate results for all players.
I also don’t understand this line
if ((currentNode.getDepth() % PLAYERS_COUNT) == static_cast<int>(result))
Unless you want to stick with your algorithm, I suggest that you look at algorithms which handle natively simultaneous moves for multiple players like DUCT or smitsimax. Given you are already familiar with MCTS, it should not be too difficult for you to implement these ones. My Olymbits PM Coding Games and Programming Challenges to Code Better may help you.
Hi, thanks for answering. My understanding is that each node should hold the win score only for the player it represent and the corresponding move. So after the playout I check who is the winner and return its index and when backpropagating I check the node depth modulo 3 (each depth holds moves for different player) if the winner idnex is equal to node.depth % 3 I increase the win score. Is this wrong idea?
My algorithm worked pretty well previously and it was the easiest to just reuse it, but I’ll definitely try smitsimax as the next step.
Maybe adding a [0, 0.5, 1] reward will help in winning second places ?
While the overall idea of your MCTS seems correct, it looks like the 3rd player has a disadvantage, as she does not really play better than random : imagine the 3rd player’s best move is D, your MCTS will only see it through the 16 paths leading to D : UUD, ULD, UDD, URD, LUD, etc. So the move counts for D are a lot fewer.
I don’t know if this is responsible for your score, sometimes very weak performances are simply due to bugs ![]()
Personally I do MCTS, each node having 64 children. In each node, i save the 12 move counts and the 12 scores of each (player, move) combination.
You should definitely update scores for all players. Being second or third is a valuable piece of information that must be backpropagated.
This looks furiously like a DUCT.
You’ve inspired me to try DUCT ![]() So the plan for me now is to make my tree with 64 branching factor and in each node I’ll store a vector of scores based on the medals count of the players. I’ll use playouts until the end of current minigames. At the end I’ll choose the best root child. This way, the backpropagation seems intuitive to me (something which I’m sure I’ve messed up in my current algorithm). The next step would be to optimize the simulations as much as possible to reach a lot search iterations.
So the plan for me now is to make my tree with 64 branching factor and in each node I’ll store a vector of scores based on the medals count of the players. I’ll use playouts until the end of current minigames. At the end I’ll choose the best root child. This way, the backpropagation seems intuitive to me (something which I’m sure I’ve messed up in my current algorithm). The next step would be to optimize the simulations as much as possible to reach a lot search iterations.
One thing that I’m wondering at the moment is what do you do on your selection step when you encounter children with 0 visits, in the literature I see advices to give these nodes UCT infinity values to prioritize them, but wouldn’t that mean that tree will grow very rapidly in width rather than depth, ending up in very low search depth (just 2-3 moves in the future)?
When you encounter a leaf, you select a random child and you backprop the result. On the next iteration, depending on UCB, you may not follow the same path. So, you may very well end up with nodes that have unexplored children. Remember to tweak the exploration factor to favor exploitation over exploration or vice versa. There is usually something to gain here.
Hi, I think there is another issue with this approach.
To simplify, imagine you are playing Rock-Paper-Scissors with 2 players.
Player 1 as implicitly the information of the move that was played by player 0 and can counter it every time.
This makes player 0 “paranoid” because it thinks all moves are bad.
Hi again @darkhorse64, I think that I’ve managed to implement DUCT on my side using your resource as a reference.
On each MCTS iteration I’m selecting nodes using DUCT, expanding the tree with 1 node and simulating a game until the 100th turn is reached or all minigames are over. This way I’ve managed to reach around 140K iterations on the first turn and around 8K on the second, does this sound reasonable? In your PM you’re mentioning:
I run 400-500k sims per 50ms during search
Is this referred to the MCTS iterations or single turn simulations for all playouts?
I’m not sure if I got your idea for the evaluation right: For each playout I first store the current medals for all players after that I use random moves for simulation, then I read the medals again, apply weights for the nonzero games count, gold medals and silver medals, I also normalize the evalaution value for each player to be in the range [-1.0; 1.0]:
playout:
playersGoldMedalsBeforePlayout[3]
playersSilverMedalsBeforePlayout[3]
randomActionsSimulation()
playersGoldMedalsAfter[3]
playersSilverMedalsAfter[3]
playersNonZeroGames[3]
for each player:
player.eval =
NON_ZERO_GAME_WEIGHT * playersNonZeroGames[p] +
GOLD_MEDALS_WEIGHT * (playersGoldMedalsAfter[p] - playersGoldMedalsBeforePlayout[p]) +
SILVER_MEDALS_WEIGHT * (playersSilverMedalsAfter[p] - playersSilverMedalsBeforePlayout[p])
player.eval /= MAX_EVAL
player.eval = player.eval * 2 - 1
And afterwards I’m backpropagating these evals in the tree
Does that make sense or I again got the idea wrong, with this approach at the moment I cannot beat even the Silver Boss…, so I’m definitely missing something important?
My figures are for single turn simulations (one turn = play 3 moves for all games) .It depends wildly on the support computer. Rerunning the bot, I get 200-400k now.
Regarding your eval, I do not use medals for scoring but something derived from what the referee does. I have not tried anything else but, imho, you are missing the individual games score multiplication. Scoring a medal where you have the least total should be highly rewarded.
I cannot rule out a bug in the selection or backpropagation but what you are doing looks right to me.
If you achieve silver only, it’s because of bugs. It can be in your MCTS but also in your code of the game : this one must be absolutely perfect… A simple DUCT should give you at least good gold rankings, getting to legend is a matter of good parameters tweaking I guess.
For your interest, I have 15k nodes/50ms.
For your asking about evaluation : you can do medalsAfterPlayout - medalsBeforeSimulation, I just do totalScoreAfterPlayout but other are possible and i guess they all work at least quite well…
There is a simple way to debug your sim: at each turn, try all move combinations of your opponent on the previous state. At least one of them (sometimes several because of stun states) must match the current state. Repeat until you have a perfect replay for some runs. It will take a few hours, it’s a bit tedious but you will be highly rewarded.
I’ve found and fixed several bugs in my code some them related to the simulation.
There is a simple way to debug your sim: at each turn, try all move combinations of your opponent on the previous state
I think I’ve got it right, I’ve ran a lot of games in the CG platform and at each turn I test if I could find a combination of moves leading to the current game state from the previous turn’s one.
I’ve also tried to change the evaluation to use the actual game score instead of medals, but after all this I still cannot beat even the Silver Boss…
One thing that I’ve noticed, when evaluation by the medals count, is that my bot often plays one of the games (diving) with 0 score, which is very strange.
I cannot find a bug in my MCTS, but I’ll output the visual tree iteration by iteration to be sure.
I have 15k nodes/50ms.
Twice as me ![]() so I definitely have room for improvement. But I believe that even with 8K iterations I should be able to beat at least the lower Gold bots. Just out of curiosity do you use multithreading somehow?
so I definitely have room for improvement. But I believe that even with 8K iterations I should be able to beat at least the lower Gold bots. Just out of curiosity do you use multithreading somehow?
Do you normalize the evaluation from the playout to be in the range [-1.f; 1.f] or you just return -1, 0 or 1?