Hello all, I need help with my MCTS idea. I’ll try to explain it as clear as I can.
I want to use classical MCTS adapted for this 3 player simultaneous game. I’ve already used this approach in another game and it works really well: Di_Masta Spring Challenge 2021 Puzzle. And I know that other players also use it like this: Magus Spring Challenge 2021 Post motern.
The main idea is on each turn first to prepare for the MCTS. Then to run as many MCTS iterations as possible in the given time frame. After the search I choose the best child of the root Node for the bot action.
The Tree Data Structure:
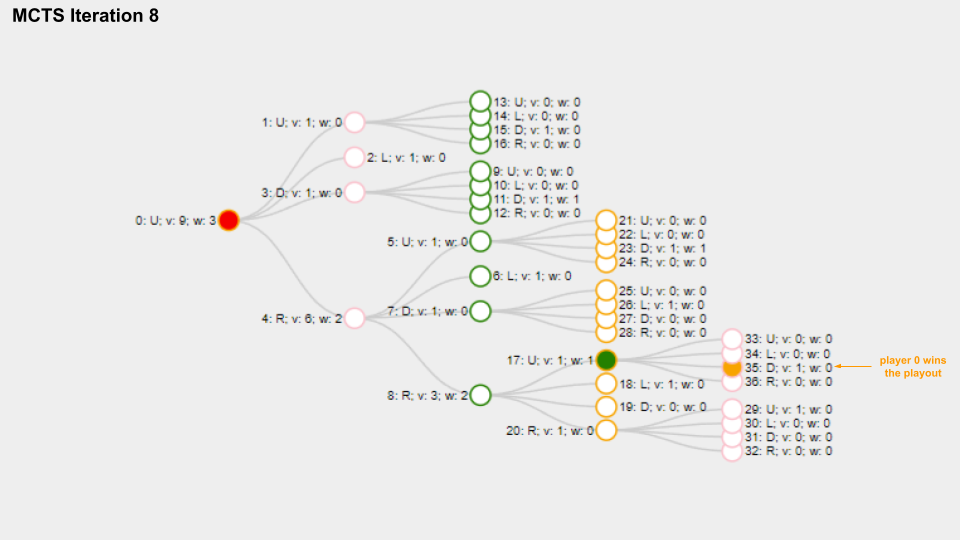
My Tree is just a very big linear array of Nodes and each Node is accessed by its index. I keep track, which Node is the root of the tree. I visualize the tree like this:
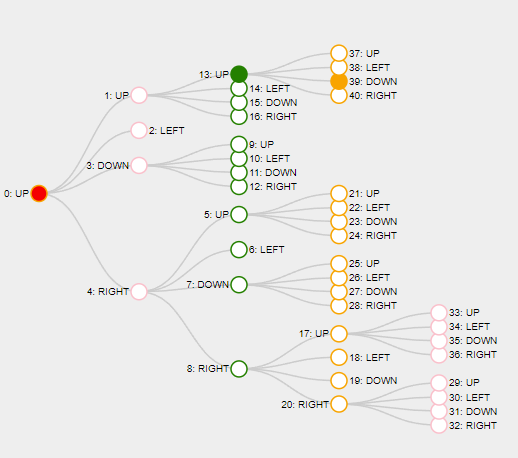
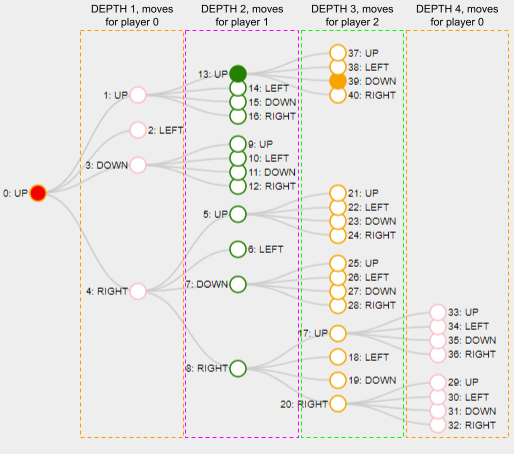
Each depth of the tree represents a move for the corresponding players:
The Node:
My Node stores a game move, the index of its parent Node, the indices for the children, depth, visits count and win score.
The Game State
I store the game state separately. It could be simulated using a sequence of moves and it could be copied, but it’s not directly stored in the search tree.
Execution:
On the 0th turn there isn’t much to prepare I just create a root Node with an invalid move. Then I start to loop for MCTS.
On each MCTS iteration:
I perform the standard SELECTION; EXPAND; PLAYOUT and BACKPROPAGATE steps as follows:
SELECTION
Starting from the root Node I traverse the tree and at each depth I choose the child with the best UCT value:
float Node::uct(const float parentVisits) const {
float value = MAX_FLOAT;
if (visits > 0.f) {
const float winVisitsRatio = winScore / visits;
const float confidentRatio = UCT_VALUE * (sqrtf(logf(parentVisits) / visits));
value = winVisitsRatio + confidentRatio;
}
return value;
}
If I have several children with MAX_FLOAT uct (not visited yet) I choose one of them at random, which I’m not sure is the CORRECT approach?
On the 0th turn and the 0th iteration the root does not have children, so it’s the selected one.
As I traverse the tree I gather the moves in a sequence from the root to the leave. Then I use this sequence for simulation from the current game state. If the sequence length is not divisible by 3 I ignore the last 1 or 2 moves, which I’ll take into account on the playout step.
EXPANSION
Then I expand the last selected leaf node with 4 children for each move.
PLAYOUT
I select one of the new children from the expansion and I simulate a random game from it onwards until I reach GAME_OVER on all 4 mini games. For the first set of moves if the selected node depth is not divisible by 3 I choose moves form it’s parents, which I’ve ignored in the selection phase
BACKPROPAGATE
When the 4 mini games have reached GAME OVER in the playout phase I decide the winner by calculating the whole game score and return the winner index. Then at each node on the path I check the depth and the winner index and increment the visits:
void MCTS::backPropagate(const int selectedNodeIdx, GameState result) {
int currentNodeIdx = selectedNodeIdx;
// Each child has bigger index than its parent
while (currentRootNodeIdx <= currentNodeIdx) {
Node& currentNode = searchTree.getNode(currentNodeIdx);
currentNode.incrementVisits();
if ((currentNode.getDepth() % PLAYERS_COUNT) == static_cast<int>(result)) {
currentNode.setWinScore(currentNode.getWinScore() + WIN_VALUE);
}
else if (GameState::DRAW == result) {
currentNode.setWinScore(currentNode.getWinScore() + DRAW_VALUE);
}
currentNodeIdx = currentNode.getParentIdx();
}
}
When the time for the turns ends I stop the search and get the child of the root with the best win score
Afterwards on the next turn I try to reuse the whole tree by checking the read game state and figuring out the opponent turns.
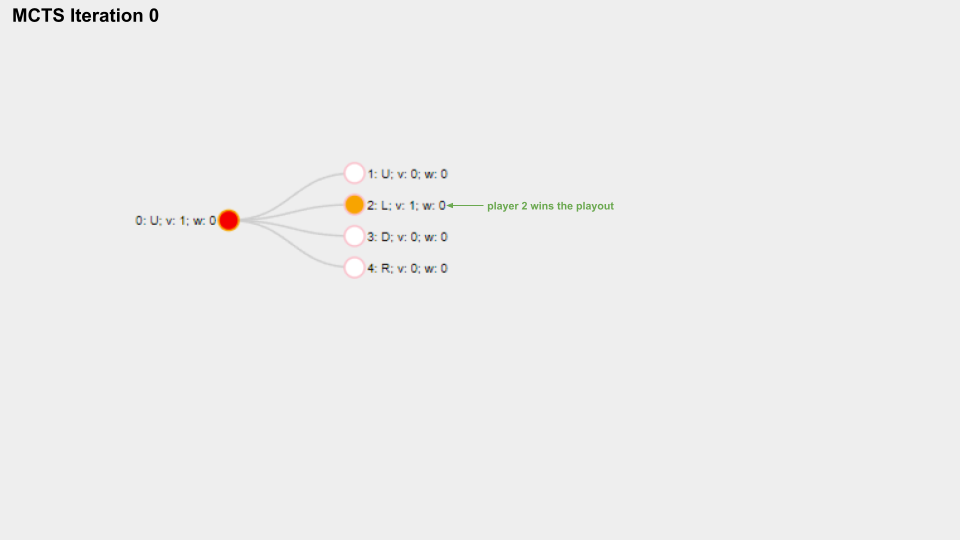
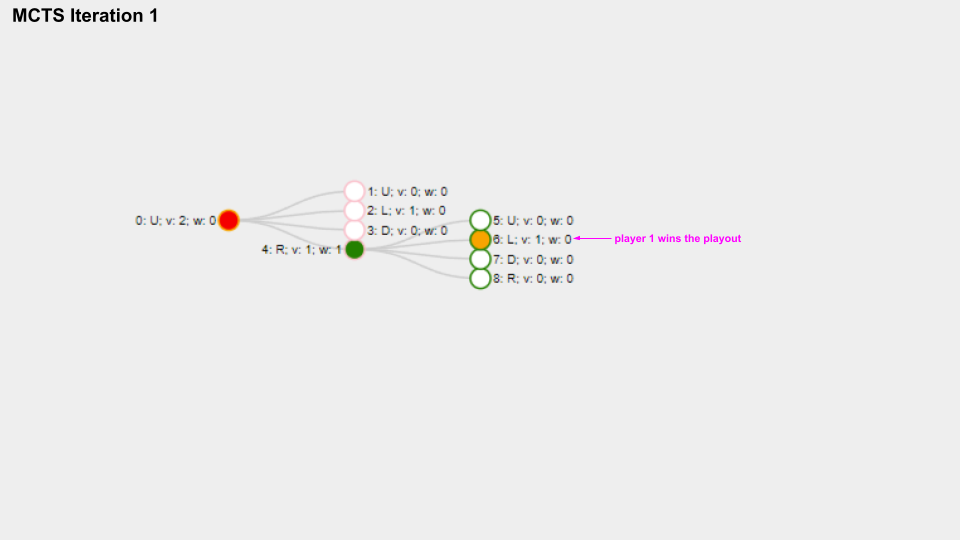
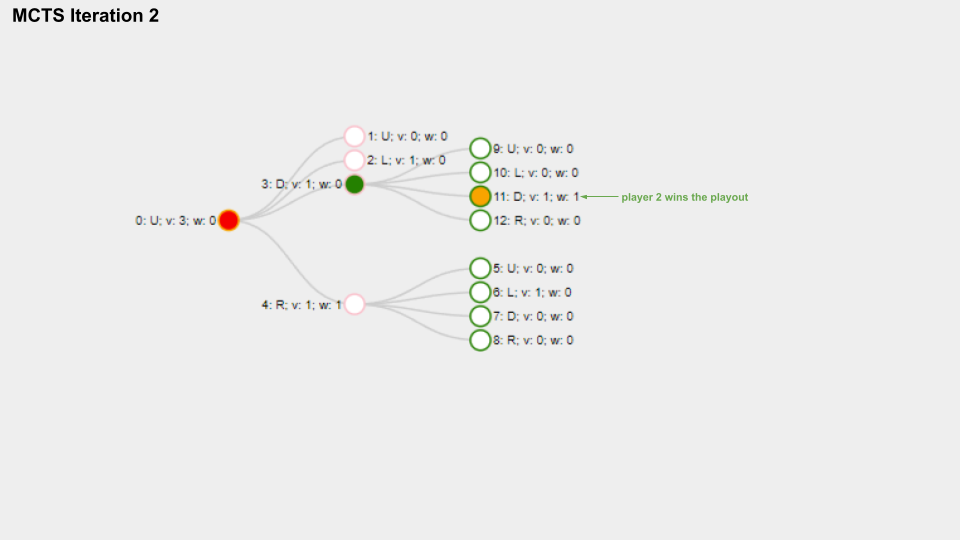
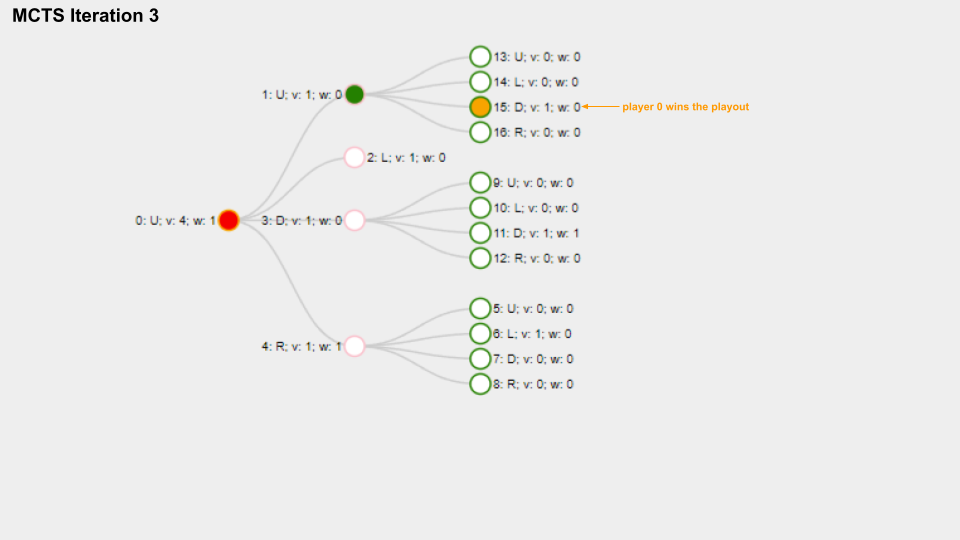
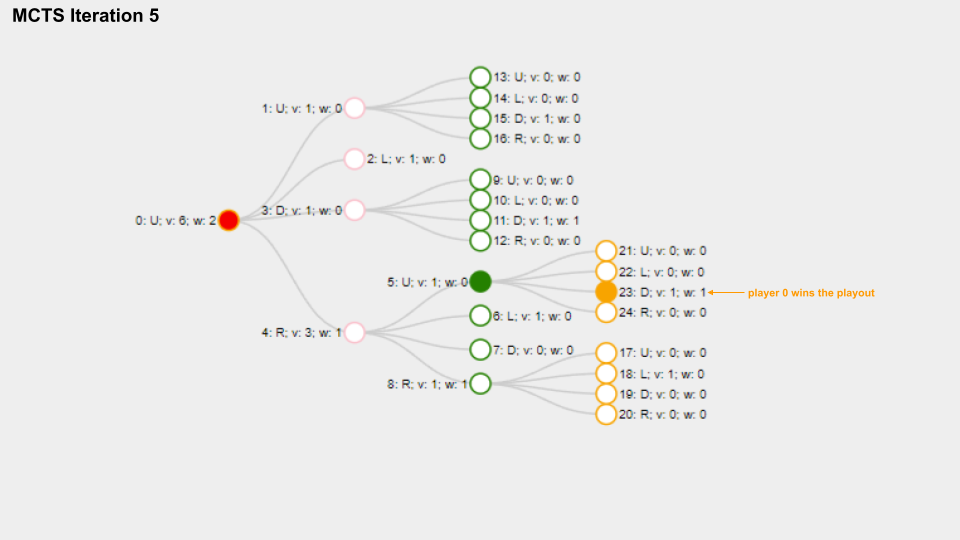
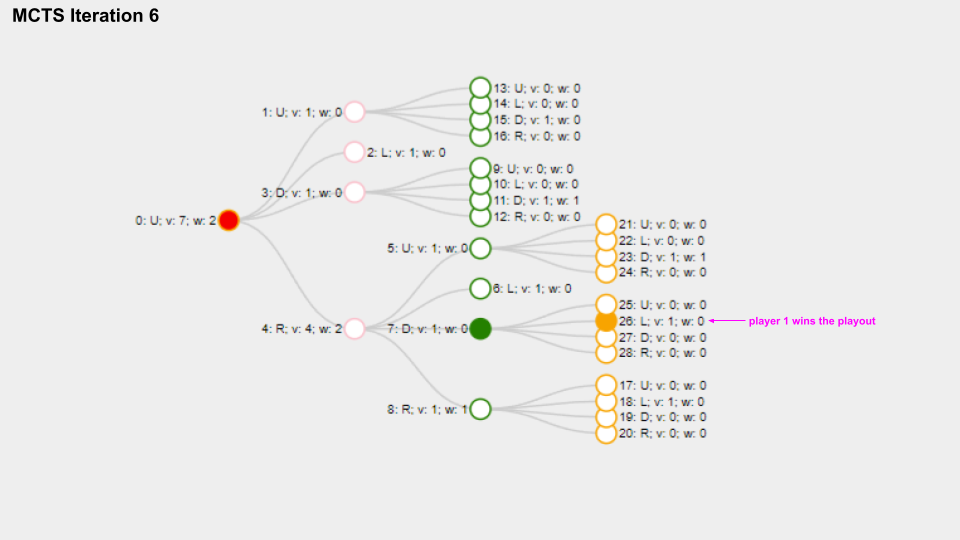
And here is a slide deck of 10 MCTS iterations.
With solid green circle I mark the Node which is selected on the selection phase, with solid orange color I mark the Node chosen for the playout phase.
The name for each Node is composed like this “Index: Move letter; v: Visits count; w: Win score”



I know this approach is not something impressive, I believe that is has potential, but obviously I’m making something very wrong could someone suggest me what to try? At the moment I cannot even win against the bottom Gold bots even though I’m making around 150K MCTS iterations on the first turn and 10K on the second, which I think is not bad.